Cluster Autoscaler: как он работает и решение частых проблем
Что такое Cluster Autosc
Kubernetes представляет несколько механизмов для масштабирования нагрузки. Три главные механизмы это : VPA, HPA, CA.
CA автоматически подбирает количество нод в кластере под требования. Когда число подов, которые находятся в очереди назначения или при остутствии возможности назначить, показывает что ресурсов не хватает в кластере, CA добавляет новые ноды в кластер. Он так же может уменьшить количество нод если они не до конца используются долгое время.
TheОбычно Cluster Autoscaler isустанавливается typicallyкак installed as aобъект Deployment objectв inкластере. aОн cluster.работает Itтолько scalesодной oneрепликой replicaи atиспользует aвыборный time,механизм andдля usesтого. leaderчтобы electionбыть toуверенным, ensureчто highон availability.
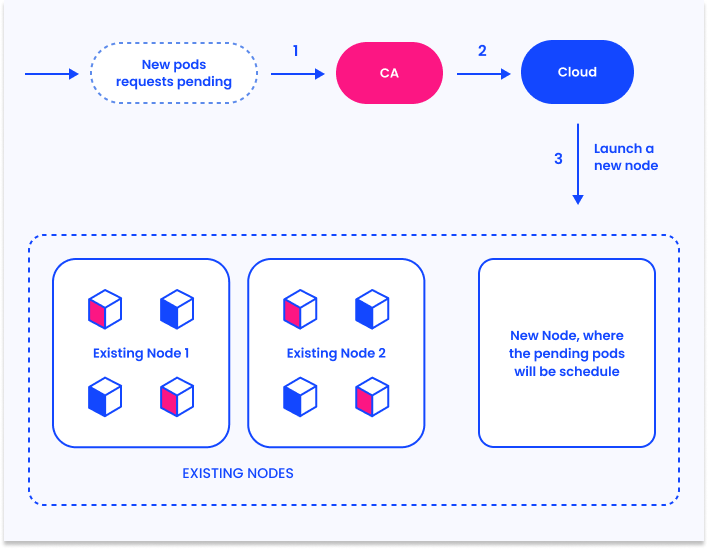
HowКак работает Cluster Autoscaler
Для простоты, мы объясним процесс Cluster Autoscaler Worksв
Forрежиме simplicity,масштабирования. we’llКогда explainчисло theназначенных Clusterподов Autoscalerв processкластере inувеличивается, aуказывая scaleна outнедостаток scenario. When the number of pending (unschedulable) pods in the cluster increases, indicating a lack of resources,ресурсов, CA automaticallyавтоматически startsзапускает newновые nodes.ноды.
ThisЭто occursпроявляется inв fourчетырех steps:шагах:
- CA
checksпроверяетforназначенныеpendingподы,pods,времяscanning at an interval ofпроверки 10secondsсекунд(для(configurableнастройкиusingможноtheуказать флаг--scan-interval)flag). IfЕслиthereестьareназначенныеpending pods,поды, CAspinsзапускаемupновыеnewнодыnodesдляtoмасштабированияscaleкластера,outвtheрамкахcluster,конфигурацииwithin the constraints configured by the administrator.кластера. CAintegratesвстраиваетсяwithвpublicоблачнуюcloudплатформу,platforms such asнапример AWSandили Azure,usingиспользуяtheirихautoscalingвозможностиcapabilitiesмасштабированияtoдляaddтого,moreчтобыvirtualможноmachines.было управлять vm.KubernetesK8sregistersрегистрируетtheновыеnewvmvirtualвmachinesкачествеasнод,nodesпозволяяinK8stheзапускатьcontrolподыplane,наallowingсвежихthe Kubernetes scheduler to run pods on them.ресурсах.TheK8sKubernetesпланировщикschedulerзапускаетassignsназначенныеtheподыpendingнаpodsновыеtoноды.the newew nodes.
DiagnosingОбнаружение Issuesпроблем withс Cluster Autoscaler
ClusterCA Autoscalerполезный isмеханизм, aно usefulон mechanism,может butработать itне canтак, sometimesкак workожидает differentlyадминистратор. thanВот expected.первшые Hereшаги, areчтобы theнайти primaryпроблему waysс to diagnose an issue with CA:CA.
LogsЛогирование onна control plane nodesнодах
KubernetesПлан controlуправления planeK8s nodesсоздает createлоги logsактивности ofCA Clusterпо Autoscalerследующему activity in the following path:пути: /var/log/cluster-autoscaler.log
Events on control plane nodesСобытия
The kube-system/cluster-autoscaler-status ConfigMap emitsпроизводят theследующие following events:события:
ScaledUpGroup—thisScaledUpGroupevent-meansэто событие говорит, CAincreasedувеличиваетtheразмерsizeгруппыofнод(предоставляетсяtheпрошлыйnodeиgroupтекущий(provides previous size and current size)размеры)ScaleDownEmpty—thisScaleDownEmptyevent-meansэто событие означение, что CAremovedубираетaноду,nodeкотораяthatнеdidимеетnotподов(системныеhaveподыanyприuserэтомpodsнеrunning on it (only system pods)рассматриваюца)ScaleDown—thisScaleDownevent-meansэто событие создается, когда CAremovedубираетaноду,nodeкотораяthatимеетhadзапущенныеuserподы.podsСобытиеrunningсодержитonименаit.всехTheподов,eventкоторыеwillбудетincludeперезазначеныtheнаnamesдругиеofнодыallвpodsрезультатеthat are rescheduled as a result.действия.
EventsСобытия on nodesнод
ScaleDown—thisTriggeredScaleUpevent-meansэто cобытие говорит, что CAisувеличиваетscalingкластер,downтакtheкакnode.появилисьThereподыcanвbe multiple events, indicating different stages of the scale-down operation.очереди.ScaleDownFailed—thisNotTriggerScaleUpevent-meansсобытие говорит, что CAtriedнеtoможетremoveувеличитьtheколичествоnodeнодbutвdid not succeed. It provides the resulting error message.группе.
Events- onэто pods
событие Cluster Autoscaler: Troubleshootingработа forс Specificопределенными Error Scenariosошибками
HereПредлагаем areнесколько specificопределенных errorситуаций, scenariosкоторые thatмогут canповяится occurпри withработе theCA Clusterи Autoscalerвозможные andрешения howэтих to perform initial troubleshooting.проблем.
TheseЭта instructionsинструкция willпозволит allowвыяснить youпростые toошибки debugработы simpleCA, errorно scenarios,для butболее forсложных moreпроблем, complexвключающие errorsмножество involvingдвигающихся multipleчастей movingв partsкластере, inвозможно theпридется cluster,автоматизировать youинструментарий mightрешения need automated troubleshooting tools.проблем.
NodesНоды withс Lowнедостаточной Utilizationнагрузой areне Notудалются Scaledиз Downкластера.
HereВот areпричины reasonsпо whyкоторы CA mightне failможет toуменьшить scaleколичество downнод, aи node,что andможно whatс youэтим can do about them.сделать.
CA --scale-down-unneeded-time --scale-down-delay-after-add--scale-down-delay-after-failure, --scale-down-delay-after-delete, --scan-interval |
|
PendingПоды Nodesв Existсостоянии Butpenind, Clusterно Doesновые Notноды Scaleне Upсоздаются.
HereНиже areприведены reasonsпричины whyпочему CA mightможет failне toувеличивать scaleколичество upнод theв cluster,кластере, andи whatчто youс canэтим doможно about them.сделать.
NoVolumeZoneConflict error—this indicatesпоказывает, that aчто StatefulSet needsтребует toзапуск runв inтой theже sameзоне zoneчто withи a PersistentVolume (PersistentVolume(PV), butно thatэта zoneзона hasуже alreadyимеет reachedдоступный itsлимит scaling.| limit.начиная
Cluster Autoscaler Stopsпрекратил Workingработать
IfЕсли CA appearsне toработает, haveпройдитесь stoppedпо working,следующим followшагам, theseчтобы stepsпонять to debug the problem:проблему.
CheckПроверьтеifчто CAisзапущен.running—youЭтоcanможноcheckпроверитьtheпоlatestпоследнемуeventsсобытию,emittedкотороеbyгенерируетсяtheвkube-system/cluster-autoscaler-statusConfigMap.ThisОноshouldнеbeдолжноno more thanпревышать 3minutes.минуты.CheckПроверьтеifеслиclusterкластерandиnodeгруппыgroupsнодareнаходятсяinвhealthyздоровомstate—thisсостоянии,shouldэтоbeтакreportedжеbyможноtheнайтиConfigMap.в configMapCheckПроверьтеifналичиеthereнеготовыхareнод - если какие-то ноды оказываютсяunreadynodesпроверьте(CAчислоversionresoureceUnready.1.24Еслиandкакие-тоlater)—ifнодыsomeпомечены,nodesпроблема,appearскорейunready,всего,checkвtheтом,resourceUnreadyчтоcount.неIfбылоanyустановленноnodesнеобходимоеare marked as resourceUnready, the problem is likely with a device driver failing to install a required hardware resource.ПО.IfЕслиboth cluster andсостояние CAareиhealthy,кластераcheck:здоровое,Nodes with low utilization—if these nodes are not being scheduled, see the Nodes with Low Utilization section above. ju* Pending pods that do not trigger a scale up—see the Pending Nodes Exist section above.
- Control plane CA
logs—couldlogsindicate-whatмогутisуказатьtheнаproblemпроблему,preventingкотораяCAможетfromнеscalingдаватьupмасштабироватьor down, why it cannot remove a pod, or what was the scale-up plan.кластер. - CA
eventsсобытияon theдля podobject—couldобъектаprovide—cluesможетwhyдать понимание почему CAcouldнеnotпереназначаетreschedule the pod.поды. - Cloud provider resources quota—
ifthereеслиareестьfailedнеудачныеattemptsпопыткиtoдобавитьaddноду,nodes,проблемаtheможетproblemбытьcouldвbeквотахresourceресурсовquotaуwith the public cloud provider.провайдера. - Networking issues—
iftheеслиcloudпровайдерproviderпытаетсяisсоздатьmanagingноду,toноcreateонаnodesнеbutподключаетсяtheyкareкластеру,notэтоconnectingможетtoговоритьtheоcluster,проблемеthisсcould indicate a networking issue.сетью.