Курс молодого бойца
- Инструментарий
- Логирование и Анализ
- Облачные сервисы
- Сети
- Настройка статического сайта с помощью Nginx
- DNS, DHCP, маршрутизация.
- Nginx, как частный пример сервера.
- Пример настройки iptables
- Ansible
- Devops
- Docker
- Перенос docker на отдельный раздел.
- Примеры команд Docker.
- Docker - инструмент создания инфраструктуры.
- Dockerfile, создание docker image.
- Containerd
- Docker swarm
- Docker-compose
- Gitlab
- Подготовка сервера для обновления версии приложения.
- Пример создания Pipeline на основе Gitlab-ci.
- Производство ПО как конвеер.
- Helm
- Helmfile
- Jenkins
- Kubernetes
Инструментарий
Мониторинг нагрузки. Zabbix.
EFK/ELK стеки.
Sentry
Percona
Запустить Percona Monitoring and Management (PMM) и PostgreSQL в Docker, чтобы не устанавливать ничего на хост.
1. Запуск PMM Server + PostgreSQL в Docker Compose
Создайте файл docker-compose.yml:
version: '3'
services:
# PMM Server
pmm-server:
image: percona/pmm-server:2
container_name: pmm-server
restart: unless-stopped
ports:
- "80:80" # Веб-интерфейс
- "443:443" # HTTPS (опционально)
volumes:
- pmm-data:/srv # Для хранения данных
environment:
- PMM_DEBUG=1 # Для отладки (опционально)
# PostgreSQL для мониторинга
postgresql:
image: postgres:13
container_name: postgresql
restart: unless-stopped
environment:
POSTGRES_USER: postgres
POSTGRES_PASSWORD: postgres
POSTGRES_DB: test_db
ports:
- "5432:5432" # Порт PostgreSQL
volumes:
- postgres-data:/var/lib/postgresql/data
# PMM Client (для мониторинга PostgreSQL)
pmm-client:
image: percona/pmm-client:2
container_name: pmm-client
restart: unless-stopped
depends_on:
- pmm-server
- postgresql
environment:
- PMM_SERVER=http://pmm-server:80
- PMM_USER=admin # Логин PMM (по умолчанию)
- PMM_PASSWORD=admin # Пароль PMM (по умолчанию)
cap_add:
- NET_ADMIN # Нужно для сбора метрик
volumes:
- /var/run/docker.sock:/var/run/docker.sock # Для мониторинга Docker
volumes:
pmm-data:
postgres-data:
2. Запуск и настройка
-
Запустите контейнеры:
docker-compose up -d -
Добавьте PostgreSQL в мониторинг:
docker exec -it pmm-client pmm-admin add postgresql \ --username=postgres \ --password=postgres \ --server-url=http://pmm-server:80 \ --service-name=postgresql-docker--usernameи--password— учётные данные PostgreSQL.--service-name— имя сервиса в PMM.
-
Проверьте статус:
docker exec -it pmm-client pmm-admin statusДолжно появиться что-то вроде:
Service type Service name Address and Port Status PostgreSQL postgresql-docker postgresql:5432 RUNNING
3. Проверка в PMM UI
- Откройте веб-интерфейс PMM:
http://localhost:80 (или IP вашего сервера). - Перейдите в PostgreSQL → Overview.
- Если данные не отображаются:
- Проверьте логи PMM Client:
docker logs pmm-client - Убедитесь, что PostgreSQL доступен из контейнера
pmm-client:docker exec -it pmm-client psql -h postgresql -U postgres -c "SELECT 1"
- Проверьте логи PMM Client:
4. Дополнительные настройки
Настройка pg_stat_statements (для мониторинга запросов)
- Подключитесь к PostgreSQL:
docker exec -it postgresql psql -U postgres - Включите расширение:
CREATE EXTENSION pg_stat_statements; ALTER SYSTEM SET shared_preload_libraries = 'pg_stat_statements'; - Перезапустите PostgreSQL:
docker restart postgresql
Настройка Alertmanager (опционально)
Если нужны уведомления (Slack, Email), настройте Alertmanager в PMM через веб-интерфейс (Alerting → Alertmanager).
Вывод
Всё в Docker:
- PMM Server (
pmm-server) — сбор и визуализация метрик. - PostgreSQL (
postgresql) — СУБД для мониторинга. - PMM Client (
pmm-client) — агент, который отправляет данные в PMM.
Логирование и Анализ
Анализ логов.
Классификация логов
- доступа (access_log) — записывают IP-адрес, время запроса, другую информацию о пользователях;
- ошибок (error_log) — показывают файлы, в которых выявлены ошибки и классифицируют сбои;
- загрузки системы — с его помощью выполняется отладка при появлении проблем, в файл записываются основные системные события, включая сбои;
- основной — содержит информацию о действиях с файерволом, DNS-сервером, ядром системы, FTP-сервисом;
- баз данных — хранит подробности о запросах, сбоях, ошибки в логах сервера отображаются наравне с другой важной информацией;
- веб-сервера — содержит информацию о возникавших ошибках, обращениях;
Для чего необходим анализ логов.
- Анализ работы приложения
- Анализ работы инфраструктуры.
Journalctl - инструмент работы системы
Systemd
- systemd — менеджер системы и сервисов
- systemctl — утилита для просмотра и управление статусом сервисов
- systemd-analyze — предоставляет статистику по процессу загрузки системы, проверяет корректность unit-файлов и так же имеет возможности отладки systemd
Место где можно найти конфигурации сервисов, демонов /etc/systemd/system/
- Journald - системный демон журналов systemd. Systemd спроектирован так, чтобы централизованно управлять системными логами от процессов, приложений и т.д. Все такие события обрабатываются демоном journald, он собирает логи со всей системы и сохраняет их в бинарных файлах.
Команды:
Отображение всех логов системы
journalctl
-e - отматает в самый конец
-f - следить за логами в реальном времени.
Фильтрация по важности
journalctl -p 0
Уровни важности:
- 0: emergency (неработоспособность системы)
- 1: alerts (предупреждения, требующие немедленного вмешательства)
- 2: critical (критическое состояние)
- 3: errors (ошибки)
- 4: warning (предупреждения)
- 5: notice (уведомления)
- 6: info (информационные сообщения)
- 7: debug (отладочные сообщения)
Фильтрация по старту системы
journalctl -b 0
- 0 - текущая загрузка
- -1 - прошлая загрузка
Фильтрация сообщений ядра
journalctl -k
Фильтрация сообщений определенного сервиса
journalctl -u NetworkManager.service
Четыре типа метрик прометея
Метрики прометея
First things first. There are four types of metrics collected by Prometheus as part of its exposition format:
- Счетчики
- Датчики
- Гистрограммы
- Сводка
Прометей ходит по HTTP точками доступа, которые выставляют метрики. Они могут быть естественно выставлены компонентом, который мониторится или может выставляться через один из сотни экспортеров прометея созданными сообществом. Прометей предоставляет клиентские библиотеки для различных языков программирования, которые вы можете использовать в своейм коде.
Модет сбора работает хорошо, когда мониторится K8s кластер, благодаря обнаружению сервисов и распределенной общей сети внутри кластера, но сложнее мониторить когда это динамический набор машин, AWS Fargate контейнеры или Lambda функции с Прометеем. Почему?
Сложно определить точки сбора метрик, и доступы к этим точкам могут быть ограниченны сетевой политикой. Чтобы решить некоторые из этих проблем, сообщество выпустило Prometheus Agent Mode в конце 2021 года, который собирает только метрики и посылает их в систему мониторинга используя удаленный протокол записи.
Прометей может собирать метрики в обоих видах Prometheus exposition и the OpenMetrics. В обоих случаях, метрики выставленны через HTTP и используют простые форматы основанные на текстах(в основном широко известные) или более эффективные и крепкие форматы буферизировнных протоколов. Одно большое преимущество текстовых форматов то, что они легко воспринимаются человеком, что значит вы можете открыть в браузере или использвать инструменты типа curl, чтобы получить текущее состояние метрик.
Прометей использует очень простую модель с четырьмя типами метрик, которые поддерживаются в клиентской библиотеке. Все виды метрик отражены в формате выставления использующий один или набор простых типов данных лежащих уровнем ниже. Тип этих данных включает название метрики, набор маркировок, и значения с плавающей запятой. Отметка времени добавляется сервером мониторинга в момент сбора данных.
Каждый уникальный набор имени метрик и набор маркрировок определяет цепь с отметками времени и занченями с плавающей запятой.
Некоторые договоренности используются для отражения различных типов метрик.
Очень полезное свойство форматов Прометея в том, что он может объединять метаданные с метриками для определени их типа и предоставления описания. Например: Прометей делает эту инфу доступной, а Графана использует её, чтобы отражить контекст пользователю, которй помогает им выбрать правильные метрики и применить правильные функции PromQL
Исследование метрик в Графана отражает список прометейских метрик и показывает дополнительный контекс о них.
Пример формата метрик получаемых Прометеем:
# HELP http_requests_total Total number of http api requests
# TYPE http_requests_total counter
http_requests_total{api="add_product"} 4633433
# HELPиспользуется для предоставления описания метрик, а# TYPEтип метрики.
Теперь посмотрим подробнее на кажду из метрик Прометея в формате вывода.
Счетчики
Счетчики используются для измерения которые только увеличиваются. Отсюда они всегда складывают их значения и могут только увеличиваться. Одно исключение: когда счетчик перезапущен, в этом случае значение сбрасывается в ноль.
На самом деле значение счетчика не очень ползено само по себе. Значение счетчика часто используется для вычисления разницы между двумя временными отметками или определения изменения во времени.
Например: типичный случай использования счетчика - измерение количества API вызовов, что является измерением которое увеличивается:
# HELP http_requests_total Total number of http api requests
# TYPE http_requests_total counter
http_requests_total{api="add_product"} 4633433
Имя метрики http_request_total, у метрики есть только 1 ярылк называется api со значением add_product и значение счетчика: 4633433. Это значит, что add_product API был взыван 4 633 433 раз с последнего запуска этой метрик. Счетчики обычно помечаются _total суфиксом.
Абсолютное число не дает нам какую-то информацию, но когда используется функция rate из PromQL (или любая другая), она помогает нам понять количество запросов в секунду получаемые API. PromQL запрос ниже вычисляет средние запросы в секунду за последние 5 минут.
rate(http_requests_total{api="add_product"}[5m])
Чтобы вычислить абсолютное изменение за временной период, мы будем использвать функцию которая называется increase() в PromQL:
increase(http_requests_total{api="add_product"}[5m])
Это вернет общее количетсво чисел запросов сделанных за последние 5 минут, и это будет то же что и This would return the total number of requests made in the last five minutes, and it would be the same as multiplying the per second rate by the number of seconds in the interval (five minutes in our case):
rate(http_requests_total{api="add_product"}[5m]) * 5 * 60
Other examples where you would want to use a counter metric would be to measure the number of orders in an e-commerce site, the number of bytes sent and received over a network interface or the number of errors in an application. If it is a metric that will always go up, use a counter.
Below is an example of how to create and increase a counter metric using the Prometheus client library for Python:
from prometheus_client import Counter
api_requests_counter = Counter(
'http_requests_total',
'Total number of http api requests',
['api']
)
api_requests_counter.labels(api='add_product').inc()
Note that since counters can be reset to zero, you want to make sure that the backend you use to store and query your metrics will support that scenario and still provide accurate results in case of a counter restart. Prometheus and PromQL-compliant Prometheus remote storage systems like Promscale handle counter restarts correctly.
Gauges
Gauge metrics are used for measurements that can arbitrarily increase or decrease. This is the metric type you are likely more familiar with since the actual value with no additional processing is meaningful and they are often used. For example, metrics to measure temperature, CPU, and memory usage, or the size of a queue are gauges.
For example, to measure the memory usage in a host, we could use a gauge metric like:
# HELP node_memory_used_bytes Total memory used in the node in bytes
# TYPE node_memory_used_bytes gauge
node_memory_used_bytes{hostname="host1.domain.com"} 943348382
The metric above indicates that the memory used in node host1.domain.com at the time of the measurement is around 900 megabytes. The value of the metric is meaningful without any additional calculation because it tells us how much memory is being consumed on that node.
Unlike when using counters, rate and delta functions don’t make sense with gauges. However, functions that compute the average, maximum, minimum, or percentiles for a specific series are often used with gauges. In Prometheus, the names of those functions are avg_over_time, max_over_time, min_over_time, and quantile_over_time. To compute the average of memory used on host1.domain.com in the last ten minutes, you could do this:
avg_over_time(node_memory_used_bytes{hostname="host1.domain.com"}[10m])
To create a gauge metric using the Prometheus client library for Python you would do something like this:
from prometheus_client import Gauge
memory_used = Gauge(
'node_memory_used_bytes',
'Total memory used in the node in bytes',
['hostname']
)
memory_used.labels(hostname='host1.domain.com').set(943348382)
Histograms
Histogram metrics are useful to represent a distribution of measurements. They are often used to measure request duration or response size.
Histograms divide the entire range of measurements into a set of intervals—named buckets—and count how many measurements fall into each bucket.
A histogram metric includes a few items:
- A counter with the total number of measurements. The metric name uses the _count suffix.
- A counter with the sum of the values of all measurements. The metric name uses the _sum suffix.
- The histogram buckets are exposed as counters using the metric name with a _bucket suffix and a le label indicating the bucket upper inclusive bound. Buckets in Prometheus are inclusive, that is a bucket with an upper bound of N (i.e., le label) includes all data points with a value less than or equal to N. For example, the summary metric to measure the response time of the instance of the add_product API endpoint running on host1.domain.com could be represented as:
# HELP http_request_duration_seconds Api requests response time in seconds
# TYPE http_request_duration_seconds histogram
http_request_duration_seconds_sum{api="add_product" instance="host1.domain.com"} 8953.332
http_request_duration_seconds_count{api="add_product" instance="host1.domain.com"} 27892
http_request_duration_seconds_bucket{api="add_product" instance="host1.domain.com" le="0"}
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.01"} 0
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.025"} 8
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.05"} 1672
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.1"} 8954
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.25"} 14251
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.5"} 24101
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="1"} 26351
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="2.5"} 27534
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="5"} 27814
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="10"} 27881
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="25"} 27890
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="+Inf"} 27892
The example above includes the sum, the count, and 12 buckets. The sum and count can be used to compute the average of a measurement over time. In PromQL, the average duration for the last five minutes will be computed as follows:
rate(http_request_duration_seconds_sum{api="add_product", instance="host1.domain.com"}[5m]) / rate(http_request_duration_seconds_count{api="add_product", instance="host1.domain.com"}[5m])
It can also be used to compute averages across series. The following PromQL query would compute the average request duration in the last five minutes across all APIs and instances:
sum(rate(http_request_duration_seconds_sum[5m])) / sum(rate(http_request_duration_seconds_count[5m]))
With histograms, you can compute percentiles at query time for individual series as well as across series. In PromQL, we would use the histogram_quantile function. Prometheus uses quantiles instead of percentiles. They are essentially the same thing but quantiles are represented on a scale of 0 to 1 while percentiles are represented on a scale of 0 to 100. To compute the 99th percentile (0.99 quantile) of response time for the add_product API running on host1.domain.com, you would use the following query:
histogram_quantile(0.99, rate(http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com"}[5m]))
One big advantage of histograms is that they can be aggregated. The following query returns the 99th percentile of response time across all APIs and instances:
histogram_quantile(0.99, sum by (le) (rate(http_request_duration_seconds_bucket[5m])))
In cloud-native environments, where there are typically many instances of the same component running, the ability to aggregate data across instances is key.
Histograms have three main drawbacks:
- First, buckets must be predefined, requiring some upfront design. If your buckets are not well defined, you may not be able to compute the percentiles you need or would consume unnecessary resources. For example, if you have an API that always takes more than one second, having buckets with an upper bound ( le label) smaller than one second would be useless and just consume compute and storage resources on your monitoring backend. On the other hand, if 99.9 % of your API requests take less than 50 milliseconds, having an initial bucket with an upper bound of 100 milliseconds will not allow you to accurately measure the performance of the API.
- Second, they provide approximate percentiles, not accurate percentiles. This is usually fine as long as your buckets are designed to provide results with reasonable accuracy.
- And third, since percentiles need to be calculated server-side, they can be very expensive to compute when there is a lot of data to be processed. One way to mitigate this in Prometheus is to use recording rules to precompute the required percentiles. The following example shows how you can create a histogram metric with custom buckets using the Prometheus client library for Python:
from prometheus_client import Histogram
api_request_duration = Histogram(
name='http_request_duration_seconds',
documentation='Api requests response time in seconds',
labelnames=['api', 'instance'],
buckets=(0.01, 0.025, 0.05, 0.1, 0.25, 0.5, 1, 2.5, 5, 10, 25 )
)
api_request_duration.labels(
api='add_product',
instance='host1.domain.com'
).observe(0.3672)
Summaries
Like histograms, summary metrics are useful to measure request duration and response sizes.
A summary metric includes these items:
- A counter with the total number of measurements. The metric name uses the _count suffix.
- A counter with the sum of the values of all measurements. The metric name uses the _sum suffix. Optionally, a number of quantiles of measurements exposed as a gauge using the metric name with a quantile label. Since you don’t want those quantiles to be measured from the entire time an application has been running, Prometheus client libraries use streamed quantiles that are computed over a sliding time window (which is usually configurable). For example, the summary metric to measure the response time of the instance of the add_product API endpoint running on host1.domain.com could be represented as:
# HELP http_request_duration_seconds Api requests response time in seconds
# TYPE http_request_duration_seconds summary
http_request_duration_seconds_sum{api="add_product" instance="host1.domain.com"} 8953.332
http_request_duration_seconds_count{api="add_product" instance="host1.domain.com"} 27892
http_request_duration_seconds{api="add_product" instance="host1.domain.com" quantile="0"}
http_request_duration_seconds{api="add_product" instance="host1.domain.com" quantile="0.5"} 0.232227334
http_request_duration_seconds{api="add_product" instance="host1.domain.com" quantile="0.90"} 0.821139321
http_request_duration_seconds{api="add_product" instance="host1.domain.com" quantile="0.95"} 1.528948804
http_request_duration_seconds{api="add_product" instance="host1.domain.com" quantile="0.99"} 2.829188272
http_request_duration_seconds{api="add_product" instance="host1.domain.com" quantile="1"} 34.283829292
This example above includes the sum and count as well as five quantiles. Quantile 0 is equivalent to the minimum value and quantile 1 is equivalent to the maximum value. Quantile 0.5 is the median and quantiles 0.90, 0.95, and 0.99 correspond to the 90th, 95th, and 99th percentile of the response time for the add_product API endpoint running on host1.domain.com.
Like histograms, summaries include sum and count that can be used to compute the average of a measurement over time and across time series.
Summaries provide more accurate quantiles than histograms but those quantiles have three main drawbacks:
- First, computing the quantiles is expensive on the client-side. This is because the client library must keep a sorted list of data points overtime to make this calculation. The implementation in the Prometheus client libraries uses techniques that limit the number of data points that must be kept and sorted, which reduces accuracy in exchange for an increase in efficiency. Note that not all Prometheus client libraries support quantiles in summary metrics. For example, the Python library does not have support for it.
- Second, the quantiles you want to query must be predefined by the client. Only the quantiles for which there is a metric already provided can be returned by queries. There is no way to calculate other quantiles at query time. Adding a new quantile requires modifying the code and the metric will be available from that time forward.
- And third and most important, it’s impossible to aggregate summaries across multiple series, making them useless for most use cases in dynamic modern systems where you are interested in the view across all instances of a given component. Therefore, imagine that in our example the add_product API endpoint was running on ten hosts sitting behind a load balancer. There is no aggregation function that we could use to compute the 99th percentile of the response time of the add_product API endpoint across all requests regardless of which host they hit. We could only see the 99th percentile for each individual host. Same thing if instead of the 99th percentile of the response time for the add_product API endpoint we wanted to get the 99th percentile of the response time across all API requests regardless of which endpoint they hit. The code below creates a summary metric using the Prometheus client library for Python:
from prometheus_client import Summary
api_request_duration = Summary(
'http_request_duration_seconds',
'Api requests response time in seconds',
['api', 'instance']
)
api_request_duration.labels(api='add_product', instance='host1.domain.com').observe(0.3672)
The code above does not define any quantile and would only produce sum and count metrics. The Prometheus client library for Python does not have support for quantiles in summary metrics.
Что такое логирование.
Известно, что программисты проводят много времени, отлаживая свои программы, пытаясь разобраться, почему они не работают — или работают неправильно. Когда говорят про отладку, обычно подразумевают либо отладочную печать, либо использование специальных программ – дебагеров. С их помощью отслеживается выполнение кода по шагам, во время которого видно, как меняется содержимое переменных. Эти способы хорошо работают в небольших программах, но в реальных приложениях быстро становятся неэффективными.
Логирование
И для всего этого многообразия систем существует единое решение — логирование. В простейшем случае логирование сводится к файлу на диске, куда разные программы записывают (логируют) свои действия во время работы. Такой файл называют логом или журналом. Как правило, внутри лога одна строчка соответствует одному действию.
Уровни логирования
- debug
- info
- warning
- error
Ротация логов
Со временем количество логов становится большим, и с ними нужно что-то делать. Для этого используется ротация логов. Иногда за это отвечает сама программа, но чаще — внешнее приложение, задачей которого является чистка. Эта программа по необходимости разбивает логи на более мелкие файлы, сжимает, перемещает и, если нужно, удаляет. Подобная система встроена в любую операционную систему для работы с логами самой системы и внешних программ, которые могут встраиваться в нее.
С веб-сайтами все еще сложнее. Даже на небольших проектах используется несколько серверов, на каждом из которых свои логи. А в крупных проектах тысячи серверов. Для управления такими системы созданы специализированные программы, которые следят за логами на всех машинах, скачивают их, складывают в заточенные под логи базы данных и предоставляют удобный способ поиска по ним.
Облачные сервисы
Различные пример облаков Yandex, Microsoft, Amazon.
Что такое облака.
VPS/VDS
Сети
Настройка статического сайта с помощью Nginx
Не забудьте установить nginx, для этого используйте команду sudo apt install nginx.
Для начала создадим файл, который мы будем раздавать с помощью nginx.
Поместим в файл index.html по адресу /srv/www/test.ru текст:
<html>
<head>
<title>Приветственная страничка</title>
</head>
<body>
Привет, Мир!
</body>
</html>
Теперь добавим конфигурационный файл test.ru.conf по адресу /etc/nginx/sites-enable/ для nginx:
server {
listen 80;
server_name test.ru;
access_log /var/log/nginx/shkolapobedy.access.log;
error_log /var/log/nginx/shkolapobedy.error.log;
root /srv/www/test.ru;
index index.html;
location / {
autoindex on;
try_files $uri $uri/ =404;
}
}
Для примера приведем конфигурационные файл, которым можно заменить конфиг выше:
server {
listen 80;
server_name test.ru;
access_log /var/log/nginx/shkolapobedy.access.log;
error_log /var/log/nginx/shkolapobedy.error.log;
location / {
root /srv/www/test.ru;
autoindex on;
try_files $uri $uri/ =404;
}
}
Проверяем, что мы не допустили ошибок и конфигурация рабочая:
nginx -t
Перезапускаем:
systemctl restart nginx
Проверяем доступность сайта
Так как у нас нет своего домена и привзяанного к нему ip, то сайт не будет доступен по адресу test.ru.
Для того, чтобы исправить ситуацию необходимо внести test.ru в файл /etc/hosts
Откройте файл hosts для редактирования и внесите следующую строку:
127.0.0.1 test.ru
Теперь можно открыть браузер и зайти по адресу test.ru
Вы должны увидеть страничку, которую мы положили по адресу /srv/www/test.ru
DNS, DHCP, маршрутизация.
DNS
Что такое DNS-сервер?
Принцип работы DNS похож на поиск и вызов контактов из телефонной книги смартфона. Ищем имя, нажимаем «позвонить», и телефон соединяет нас с нужным абонентом. Понятно, что смартфон в ходе звонка не использует само имя человека, вызов возможен только по номеру телефона. Если вы внесете имя без номера телефона, позвонить человеку не сможете.
Так и с сайтом. Каждому имени сайта соответствует набор цифр формата 000.000.000.000. Этот набор называется IP-адресом, примером реального IP-адреса является 192.168.0.154 или 203.113.89.134. Когда пользователь вводит в адресной строке браузера имя сайта, например google.com, компьютер запрашивает IP-адрес этого сайта на специальном DNS-сервере и после получения корректного ответа открывает сам сайт.
Зачем нужны DNS-серверы и какие они бывают?
Основное предназначение DNS-серверов — хранение информации о доменах и ее предоставление по запросу пользователей, а также кэширование DNS-записей других серверов. Это как раз «книга контактов», о которой мы писали выше.
В случае кэширования все несколько сложнее. Дело в том, что отдельно взятый DNS-сервер не может хранить вообще всю информацию об адресах сайтов и связанных с ними IP-адресами. Есть исключения — корневые DNS-серверы, но о них позже. При обращении к сайту компьютера пользователя браузер первым делом проверяет локальный файл настроек DNS, файл hosts. Если там нет нужного адреса, запрос направляется дальше — на локальный DNS-сервер интернет-провайдера пользователя.
Локальный DNS-сервер в большинстве случаев взаимодействует с другими DNS-серверами из региона, в котором находится запрошенный сайт. После нескольких обращений к таким серверам локальный DNS-сервер получает искомое и отправляет эти данные в браузер — запрошенный сайт открывается. Полученные данные сохраняются на локальном сервере, что значительно ускоряет его работу. Поскольку, единожды «узнав» IP-адрес сайта, запрошенного пользователем, локальный DNS сохраняет эту информацию. Процесс сохранения полученных ранее данных и называется кэшированием.
Если пользователь обратится к ранее запрошенному сайту еще раз, то сайт откроется быстрее, поскольку используется сохраненная информация. Правда, хранится кэш не вечно, время хранения зависит от настроек самого сервера.
IP-адрес сайта может измениться — например, при переезде на другой хостинг или сервер в рамках прежнего хостинга. Что происходит в этом случае? В этом случае обращения пользователей к сайту, чей IP-адрес поменялся, некоторое время обрабатываются по-старому, то есть перенаправление идет на прежний «айпишник». И лишь через определенное время (например, сутки) кэш локальных серверов обновляется, после чего обращение к сайту идет уже по новому IP-адресу.
DNS-серверы верхнего уровня, которые содержат информацию о корневой DNS-зоне, называются корневыми. Этими серверами управляют разные операторы. Изначально корневые серверы находились в Северной Америке, но затем они появились и в других странах. Основных серверов — 13. Но, чтобы повысить устойчивость интернета в случае сбоев, были созданы запасные копии, реплики корневых серверов. Так, количество корневых серверов увеличилось с 13 до 123.
Что такое DNS-зоны?
- А — адрес веб-ресурса, который привязан к конкретному имени домена.
- MX — адрес почтового сервера.
- CNAME — чаще всего этот тип записи используется для подключения поддомена.
- NS — адрес DNS-сервера, который отвечает за содержимое других ресурсных записей.
- TXT — любая текстовая информация о доменном имени.
- SPF — данные с указанием списка серверов, которые входят в список доверенных для отправки писем от имени указанного домена.
- SOA — исходная запись зоны, в которой указаны сведения о сервере и которая содержит шаблонную информацию о доменном имени.
DHCP
DHCP — протокол прикладного уровня модели TCP/IP, служит для назначения IP-адреса клиенту. Это следует из его названия — Dynamic Host Configuration Protocol. IP-адрес можно назначать вручную каждому клиенту, то есть компьютеру в локальной сети. Но в больших сетях это очень трудозатратно, к тому же, чем больше локальная сеть, тем выше возрастает вероятность ошибки при настройке. Поэтому для автоматизации назначения IP был создан протокол DHCP.
Принцип работы DHCP Из вступления ясно, какие функции предоставляет DHCP, но по какому принципу он работает? Получение адреса проходит в четыре шага. Этот процесс называют DORA по первым буквам каждого шага: Discovery, Offer, Request, Acknowledgement.
Сетевая маршрутизация
Понятие «маршрутизация» включает в себя несколько значений, одно из них — это передача информации от отправителя к получателю. В ІТ-среде маршрутизацией называется аппаратное вычисление маршрута движения пакетов данных между сетями с использованием специального сетевого устройства – маршрутизатора.
Маршруты могут быть статическими и задаваться администратором сети, или динамическими и рассчитываться сетевыми устройствами по определенным алгоритмам (протоколам) маршрутизации, которые основаны на данных о топологии сети.
Виды маршрутизации:
- Различают два вида маршрутизации: программная и аппаратная.
- Программная маршрутизация — это специализированное программное обеспечение, установленное на компьютере с несколькими сетевыми интерфейсами, которые входят в состав различных сетей.
- Аппаратная маршрутизация осуществляется специальным оборудованием, способным анализировать и перенаправлять входящие потоки данных.
Что такое NAT
При проектировании сетей обычно применяются частные IP-адреса 10.0.0.0/8, 172.16.0.0/12 и 192.168.0.0/16. Их используют внутри сети площадки или организации для поддержания локального взаимодействия между устройствами, а не для маршрутизации во всемирной сети. Чтобы устройство с адресом IPv4 могло обратиться к другим устройствам или ресурсам через интернет, его частный адрес должен быть преобразован в публичный и общедоступный. Такое преобразование — это главное, что делает NAT, специальный механизм преобразования приватных адресов в общедоступные.
Терминология NAT:
- внутренний локальный — видимый во внутренней сети адрес источника, собственный локальный адрес устройства.
- внутренний глобальный — видимый из внешней сети адрес источника. При передаче трафика, например, с локального компьютера на веб-сервер, его Inside local address преобразуется маршрутизатором во внутренний глобальный адрес.
- внешний локальный — видимый из внешней сети адрес получателя. Присвоенный хосту глобально маршрутизируемый адрес IPv4.
- внешний глобальный — видимый из внутренней сети адрес получателя. Часто совпадает с локальным внешним адресом.
Типы NAT:
- Static NAT — статическая адресная трансляция. Предусматривает сопоставление между глобальными и локальными адресами «один к одному».
- Dynamic NAT — динамическая адресная трансляция. Сопоставление адресов осуществляется по принципу «многие ко многим».
- Port Address Translation (NAT Overload) — трансляция с использованием портов. Предусматривается многоадресное сопоставление.
Проброс портов.
«Пробросить» порты — это дать команду роутеру зарезервировать один порт и все приходящие на него данные для передачи на определенный компьютер. Другими словами, сделать исключение из правила отклонения неинициированных внешних запросов и принимать их при заданных условиях.
Для этого задается правило перенаправления любого свободного порта интерфейса WAN на роутере на определенный порт указанного устройства.
После того, как правило перенаправления будет создано, входящие на указанный внешний порт запросы будут адресованы указанному порту определенного устройства.
Пример такого подключения я вляется перенапралвение, когда на роутере мы указываем, что входящий запрос на 80 порт должен перевестись на определенный компьютер в локальной сети. В этом случае любой запрос из интернета на ip адрес, если он не за NAT, откроет приложение запущенно на компьютере в локальной сети.
Nginx, как частный пример сервера.
NGINX — это веб-сервер и почтовый прокси, который работает под управлением операционных систем семейства Linux/Unix и Microsoft.
Область применения
Веб-сервер применяется в следующих ситуациях:
- ыделенный порт или IP-адрес. Если на сервере присутствует большое количество статичного материала (картинки, тексты и т. д.) либо файлов для загрузки пользователями, то Nginx используют, чтобы выделить под данные операции отдельный IP-адрес либо порт. Таким образом нагрузка на сервер распределяется.
- Прокси-сервер. Когда пользователь загружает страницу сайта, на которой расположен статичный контент, Nginx сначала кэширует данные у себя, а потом возвращает результат. При следующих запросах данной страницы ответ происходит в разы быстрее.
- Распределение нагрузки. При запросе страницы сайта, пользователю выдается ответ в синхронной последовательности. Nginx использует асинхронный режим. Все запросы обрабатываются на разных этапах. Такой подход повышает скорость обработки.
- Почтовый сервер. Поскольку в веб-сервер встроены механизмы аутентификации, то его часто используют для перенаправления на почтовые сервисы после прохождении авторизации клиентом.
Установка сервера
sudo apt install nginx
Команды для взаимодействия с демоном
Запустить/остановить демон nginx
systemctl start/stop nginx
Включить/выключить автоматический запуск, --now - говорит не ждать следующий загрузки системы, а выполнить условие прямо сейчас.
systemctl disable/enable nginx --now
Проверить конфигурацию на правильность.
nginx -t
При изменении конфигурации nginx требуется перезагрузить.
Пример конфигурации:
Внимание! Конфиг ниже приведет в упрощенном виде.
worker_processes auto;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
multi_accept on;
use epoll;
}
http {
default_type application/octet-stream;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
types_hash_max_size 2048;
client_max_body_size 1G;
include /etc/nginx/mime.types;
server {
listen 80;
server_name test.ru;
# gzip begin
gzip on;
gzip_disable "msie6";
# gzip end
location /static/ {
root /code/public;
expires max;
try_files $uri$args $uri =404;
}
location / {
auth_basic "Restricted Content";
auth_basic_user_file /etc/nginx/htpasswd;
proxy_pass http://web:8080;
proxy_set_header Host $http_host;
proxy_set_header Connection "upgrade";
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Upgrade $http_upgrade;
proxy_connect_timeout 600;
proxy_send_timeout 600;
proxy_read_timeout 600;
send_timeout 600;
}
}
}
Ключевые слова, важные для нас:
- http - общие настройки сервера применяемые
- server - настройки применяемые исключительно для конкретного сервера.
- server_name - название сервера которое мы будем использовать
- listen - порт на котоом будет запущен nginx
- location - настройка различных префиксов, которые в свою очередь могут перенаправлять запросы в различные сервисы.
- include - включает конфиг, расположенный по указанному адресу
Пример настройки iptables
#./iptables_rules.sh
#! /bin/bash
IPT="iptables"
## Внешний интерфейс
WAN=ens224
WAN_IP=ВАШ_внешний_IP
## Внутренний интерфейс
LAN1=ens192
LAN1_IP=ВАШ_внутренний_IP
LAN1_IP_RANGE=192.168.0.0/24
LAN2=IP_Jitsi
## Очищаем все цепочки перед применением новых правил
$IPT -F
$IPT -F -t nat
$IPT -F -t mangle
$IPT -X
$IPT -t nat -X
$IPT -t mangle -X
## Блокируем весь трафик, который не соответствует ни одному из правил
$IPT -P INPUT DROP
$IPT -P OUTPUT DROP
$IPT -P FORWARD DROP
## Разрешаем весь трафик в локалхост и локальной сети
$IPT -A INPUT -i lo -j ACCEPT
$IPT -A INPUT -i $LAN1 -j ACCEPT
$IPT -A OUTPUT -o lo -j ACCEPT
$IPT -A OUTPUT -o $LAN1 -j ACCEPT
## Этот блок разрешает icmp-запросы (пинговать сервер) (опционально)
$IPT -A INPUT -p icmp --icmp-type echo-reply -j ACCEPT
$IPT -A INPUT -p icmp --icmp-type destination-unreachable -j ACCEPT
$IPT -A INPUT -p icmp --icmp-type time-exceeded -j ACCEPT
$IPT -A INPUT -p icmp --icmp-type echo-request -j ACCEPT
## Открываем доступ в интернет самому серверу
$IPT -A OUTPUT -o $WAN -j ACCEPT
#$IPT -A INPUT -i $WAN -j ACCEPT
## Разрешаем все установленные соединения и дочерние от них
$IPT -A INPUT -p all -m state --state ESTABLISHED,RELATED -j ACCEPT
$IPT -A OUTPUT -p all -m state --state ESTABLISHED,RELATED -j ACCEPT
$IPT -A FORWARD -p all -m state --state ESTABLISHED,RELATED -j ACCEPT
## Защита от наиболее распространенных сетевых атак. (опционально)
## Отбрасываем все пакеты без статуса (опционально)
$IPT -A INPUT -m state --state INVALID -j DROP
$IPT -A FORWARD -m state --state INVALID -j DROP
## Блокируем нулевые пакеты (опционально)
$IPT -A INPUT -p tcp --tcp-flags ALL NONE -j DROP
## Закрываемся от syn-flood атак (опционально)
$IPT -A INPUT -p tcp ! --syn -m state --state NEW -j DROP
$IPT -A OUTPUT -p tcp ! --syn -m state --state NEW -j DROP
## Запрет доступа с определенных IP (опционально)
#$IPT -A INPUT -s ipaddres -j REJECT
## Разрешаем доступ в интернет из локальной сети
$IPT -A FORWARD -i $LAN1 -o $WAN -j ACCEPT
## Запрещаем доступ из интернета в локальную сеть (опционально)
#$IPT -A FORWARD -i $WAN -o $LAN1 -j REJECT
## Чтобы в локальной сети был интернет включаем nat
$IPT -t nat -A POSTROUTING -o $WAN -s $LAN1_IP_RANGE -j MASQUERADE
##Должен быть включен ip forwarding
## Разрешаем ssh (порт 22 - это порт по умолчанию для ssh соединения, если вы его меняли, то обязательно значение 22 надо заменить своим, иначе будет потерян доступ к серверу)
$IPT -A INPUT -i $WAN -p tcp --dport 22 -j ACCEPT
## Перенаправление трафика на сервер JITSI
$IPT -A FORWARD -i $WAN -d $LAN2 -p tcp -m tcp --dport 80 -j ACCEPT
$IPT -A FORWARD -i $WAN -d $LAN2 -p tcp -m tcp --dport 443 -j ACCEPT
$IPT -A FORWARD -i $WAN -d $LAN2 -p udp -m udp --dport 10000 -j ACCEPT
$IPT -t nat -A PREROUTING -i $WAN -p tcp --dport 80 -j DNAT --to $LAN2
$IPT -t nat -A PREROUTING -i $WAN -p tcp --dport 443 -j DNAT --to $LAN2
$IPT -t nat -A PREROUTING -i $WAN -p udp --dport 10000 -j DNAT --to $LAN2
$IPT -t nat -A POSTROUTING -j MASQUERADE
Применить конфигу
chmod +x iptables_rules.sh
./iptables_rules.sh
iptables-save > /etc/iptables-conf/iptables_rules.ipv4
Ansible
Handlers
Чтобы правильно использовать Ansible handler для перезапуска systemd сервиса, вам понадобится несколько шагов. Вот примерный путь:
- Определите ваш handler в Ansible playbook. Например:
handlers:
- name: restart myservice
systemd:
name: myservice
state: restarted
- В playbook добавьте таск, который будет вызывать этот handler в случае необходимости:
tasks:
- name: Ensure myservice is running
systemd:
name: myservice
state: started
notify: restart myservice
В этом примере при обновлении или изменении сервиса "myservice" будет выполнен таск "Ensure myservice is running". Если сервис был изменен, handler "restart myservice" будет вызван автоматически для его перезапуска.
Проверьте, что у вас есть блок notify в вашем таске, чтобы указать Ansible, какой handler использовать. Убедитесь, что имя handler совпадает с именем, указанным в блоке handlers.
Запустите ваш playbook с помощью команды ansible-playbook.
После выполнения изменений, если сервис "myservice" был изменен, Ansible автоматически вызовет handler для его перезапуска.
Блоки различные блоки в ansible роли
---
- name: Задача 1
ansible.builtin.get_url:
url: "{{ docker_compose_binary_source }}"
dest: /usr/local/bin/docker-compose
- name: Задача 2
become: true
apt:
name: zip
state: present
- name: Блок задач
block:
- name: Задача 1
lineinfile:
path: /путь/к/файлу
line: 'строка_для_добавления'
- name: Check if backup file already exists
stat:
path: "/opt/{{ docker_compose_backup }}"
register: backup_file_exists
- name: Задача 2
command: "cp {{ docker_compose }} {{ docker_compose_backup }}"
args:
chdir: "{{ project_path }}"
when: not backup_file_exists.stat.exists
rescue:
- name: Задача восстановления при сбое выполнения задач в блоке выше
debug:
msg: "Failed to process Docker Compose file."
- name: Задача 3
command:
cmd: "docker-compose up -d"
args:
chdir: "{{ project_path }}"
- name: Задача 4
file:
path: "/opt/{{ sentry_version }}.zip"
state: absent
ignore_errors: true
Devops
Что такое CI\CD
CI\CD содержит три основных момента:
- Continuous Integration (CI)
- Continuous Delivery (CD)
- Continuous Deployment (CD)
Этапы
- Написание кода.
- Сборка.
- Ручное/Автоматические тестирование.
- Релиз.
- Развертывание.
- Поддержка и мониторинг.
- Планирование.
Цели
- Сегрегация отвественности
- Снижение риска
- Короткий цикл обратной сязи.
Состав команды.
- Разработчики и дизайнеры (Dev)
- Инженеры по качеству (QA)
- Бизнес-аналитики (BAs) и владельцы продуктов (POs)
- Оперативный отдел (Ops)/ DevOps-инженеры
- Пользователи
Инструменты
- GitLab, Github.
- Docker, Kubernetes
- Travis-CI, Circle-CI, Jenkins, TeamCity
Что такое Devops
DevOps — это культура, которая способствует сотрудничеству между группой разработки и эксплуатации для более быстрого и автоматизированного развертывания кода в производстве. Слово «DevOps» представляет собой сочетание двух слов «разработка» и «операции».
DevOps помогает повысить скорость организации для доставки приложений и услуг. Это позволяет организациям лучше обслуживать своих клиентов и более активно конкурировать на рынке.
Проще говоря, DevOps можно определить как согласование процессов разработки и ИТ с улучшением взаимодействия и совместной работы.
Почему DevOps используется?
DevOps позволяет командам Agile Development реализовывать непрерывную интеграцию и непрерывную доставку. Это помогает им быстрее выводить продукты на рынок.
Другие важные причины:
- Предсказуемость
- Воспроизводимость
- Ремонтопригодность
- Время выхода на рынок
- Повышенное качество
- Снижение риска
- Отказоустойчивость
- Экономическая эффективность
- Разбивает большую кодовую базу на маленькие кусочки
Жизненный цикл DevOps
- Разработка
- Тестирование
- Интеграция
- Развертывание
- Мониторинг
Цели DevOps
Вот шесть принципов, которые необходимы при принятии DevOps:
- Ориентация на клиента
- Непрерывная ответственность
- Постоянное улучшение
- Автоматизируйте все
- Работайте одной командой
- Контролируйте и тестируйте все
Кто такой инженер DevOps?
DevOps Engineer — это ИТ-специалист, который работает с разработчиками программного обеспечения, системными операторами и другими производственными ИТ-специалистами для администрирования выпусков кода. DevOps должен обладать как сложными, так и мягкими навыками общения и совместной работы с командами разработчиков, тестирования и эксплуатации.
Подход DevOps требует частых, постепенных изменений версий кода, что означает частые схемы развертывания и тестирования. Хотя инженерам DevOps нужно время от времени писать код с нуля, важно, чтобы они имели основы языков разработки программного обеспечения.
Инженер DevOps будет работать с персоналом команды разработчиков, чтобы заняться кодированием и сценариями, необходимыми для соединения элементов кода, таких как библиотеки или наборы для разработки программного обеспечения.
Роли, обязанности и навыки инженера DevOps
Инженеры DevOps работают полный рабочий день. Они несут ответственность за производство и текущее обслуживание платформы программного приложения.
Ниже приведены некоторые ожидаемые роли, обязанности и навыки, которые ожидаются от инженера DevOps:
- Способен выполнять поиск и устранение неисправностей системы в разных областях платформы и приложений.
- Эффективное управление проектом через открытые, основанные на стандартах платформы
- Повысить видимость проекта и прослеживаемость
- Улучшение качества и снижение затрат на разработку с помощью совместной работы
- Анализировать, проектировать и оценивать скрипты и системы автоматизации
- Обеспечение критического разрешения системных проблем с использованием лучших сервисов облачной безопасности.
- Инженер DevOps должен обладать умением решать проблемы и быстро учиться
Linux\Bash Работа в командной строке.
Права доступа к файлам
У файла есть три группы владельцев:
- User(пользователь)
- Group(группа)
- Other(все другие)
Каждой группе назначается права доступа:
- Read(Чтение)
- Write(Запись)
- Execute(Выполнение)
Рассмтрим пример Выолните в командной строке:
ls -l
В ответ мы получим вывод следующего вида:
-rw-r--r--. 1 user user 478 сен 6 16:42 index.html
-rwxr-xr-x. 1 user user 1244 июл 30 10:37 modules
drwxr-xr-x. 5 user user 4096 сен 10 15:58 Pictures
drwxr-xr-x. 2 user user 4096 янв 24 2021 Public
drwxr-xr-x. 13 user user 4096 авг 17 09:12 Repos
Разрберем запись:
drwxr-xr--
Нотация имеет группы свойств:
-
dили-укзание того, что перед нами файл или папка. -
rwx- позволяет пользователю читать(r), писать(w), исполнять(x) этот файл -
r-x- позволяет группе пользователей читать(r), но не писать в него (-), испольнять(x) -
r-x- позволяет всем остальным читать(r), но не писать в него (-), не испольнять(-)
--- - подразумевает что у владельца, группы или остальных нет никаких разрешений вообще.
CHMOD
Довольно часто для смены прав доступа используется команда chmod.
chmod permissions filenam
Используя табилцу ниже файлу или папке можно дать различные права:
| Число | Тип разрешения | Символ |
|---|---|---|
| 0 | Отсутствует разрешение на | --- |
| 1 | Выполнение | --x |
| 2 | Запись | -w- |
| 3 | Выполнение+ Запись | -wx |
| 4 | Чтение | r-- |
| 5 | Чтение+Выполнение | r-x |
| 6 | Чтение+Запись | rw- |
| 7 | Чтение+Запись+ВЫполнение | rwx |
CHOWN
Команда для изменения владельца файла\каталога
chown user:group filename
Возьмем пример выше
-rwxr-xr-x. 1 user user 1244 июл 30 10:37 modules
Если мы воспользуемся командой chown:
chown test:group modules
То в результате user должен смениться на test, и user на group, и при проверке прав мы увидим следующие изменения:
-rwxr-xr-x. 1 test group 1244 июл 30 10:37 modules
Перенаправление ввода
">"
Этот символ используется для перенаправления вывода(stdout)
Пример:
la -al > file.txt
В этом случае всё что выведется командой la -al будет записано в file.txt, при этом на экране ничего не отобразиться.
Можно рассмотреть следующий пример:
cat music.mp3 > /dev/audio
Команда cat прочитает файл music.mp3 и вместо того чтобы вывести его в терминал отправит в устройство /dev/audio, если у вас в системе есть такое устройство то вы услышите этот файл из колонок.
"<"
Этот символ используется для перенаправления ввода(stdin)
Пример:
mail -s "subject" to-address < Filename
Команда прикрепит Filename к письму и отправит его по адресу to-address.
Перенаправление ошибок
Всякий раз когда выполняется программа открыто 3 файла:
- standard input -- FD0
- standard output -- FD1
- standard error -- FD2
FD - файловый дескриптор. В Linux / Unix все является файлом. Обычный файл, каталоги и даже устройства являются файлами. Каждый файл имеет связанный номер, называемый дескриптором файла (FD).
примеры использования:
- Вывод ошибок программы
myprogramперенаправляется в errorfile. В этом случае ошибки не отображются при выполнении командыmyprogram.
myprogram 2>errorsfile
- С помощью
findмы ищем в текущем каталоге.фалй начинающийся сmy. При этом все ошибки описка отправляются в файлerror.log
find . -name 'my*' 2>error.log
- Команда выводит список файлов в двух директориях
DocumentsиABC, в свою очередь2>&1переводи вывод ошибок в стандартный вывод. То естьstderrперенаправляется вstdout. И весь вывод записывается в файл dirlist
ls Documents ABC> dirlist 2>&1
Pipeline
Pipeline - комбинация команд передающая аргументы друг другу после выполнения. Т.е. вывод команды является вводом следующей команды
Например, ниже мы передаем вывод команды cat на вход команды less:
cat filename | less
grep
Создадим файл example.txt, внесем в него какие-либо строки и выведем его:
cat example.txt
Команда grep выведет искомые данные. Синтаксис использования: grep ИСКОМОЕ_ВЫРАЖЕНИЕ:
cat example.txt | grep dog
Команда grep пройдется по выводу команды cat и отразит только строки содержащие dog.
Ключи команды grep:
| ключь | функция |
|---|---|
| -v | Показывает все строки, которые не соответствуют искомой строке |
| -с | Отображает только количество совпадающих строк |
| -n | Показывает совпадающую строку и ее номер |
| -l | Показывает только имя файла со строкой |
sort
Сортирует содержимое в алфавитном порядке
Команда sort выведет искомые данные. Синтаксис использования: sort ФАЙЛ.
sort example.txt
Ниже приведен вариант использования sort в комбинации с командой grep в pipeline:
cat example.txt | grep -v a | sort -r
grep выведет все строки не содержащие букву a, а затем отсортирует их в обратном алфавитном порядке.
Регулярные выражения
Регулярные выражения — это специальные символы, которые помогают искать данные, соответствующие сложным шаблонам. Регулярные выражения сокращаются до ‘regexp’ или ‘regex’.
Основные Регулярные выражения
| Символ | Описания |
|---|---|
| , | заменяет любой символ |
| ^ | соответствует началу строки |
| $ | соответствует концу строки |
| * | соответствует нулю или более раз предыдущего символа |
| \ | Представляют специальные символы |
| () | Группы регулярных выражений |
| ? | Соответствует ровно одному символу |
Интервал в регулярных выражениях
| Выражение | Описание |
|---|---|
| {n} | Соответствует предыдущему символу, появляющемуся n раз точно |
| {n,m} | Соответствует предыдущему символу, появляющемуся n раз, но не более чем m |
| {n,} | Соответствует предыдущему символу, только если он появляется n раз или более |
Примеры использования:
Создадим файл example.txt и внесем в него какой-то текст
Чтобы посмотреть содержимое выполним:
cat example.txt
Выведет все строки содержащие букву a
cat example.txt | grep a
Выведет все строки начинающиеся с буквы a
cat example.txt | grep ^a
Выведет все строки заканчивающиеся на t
cat example.txt | grep t$
Выведет строки где символ p идет 2 раза подряд
cat example.txt | grep -E p\{2}
Docker
Перенос docker на отдельный раздел.
Первый вариант
Останавливаем docker
systemctl stop docker
systemctl stop docker.socket
Обновляем конфигурацию daemon
echo '{ "data-root": "/new_dir_structure/docker" }' > /etc/docker/daemon.json
Запускаем docker
systemctl start docker
Второй вариант
Создаем отдельный раздел для docker
тут должен быть код для создания отдельного раздела на диске\
можно воспользоваться инструментами типа gparted
Останавливаем docker
systemctl stop docker
systemctl stop docker.socket
Прописываем fstab строчку, чтобы монтирование происходило в /var/lib/docker
Этот шаг может быть выполнен в момент создания раздела, если использовать графическую оболочку.
/dev/disk/by-uuid/ID-УСТРОЙСТВА /var/lib/docker auto nodev,nofail 0 0
или
/dev/sda(НОМЕР_УСТРОЙСТВА) /var/lib/docker auto nodev,nofail 0 0
Запускаем docker
systemctl start docker
Проверяем что всё работает
docker run nginx
Если возникает ошибка
Можно встретить вот такую ошибку:
/bin/sh: error while loading shared libraries: /lib/x86_64-linux-gnu/libc.so.6: cannot apply additional memory protection after relocation: Permission denied
для решения можно воспользоваться вот такой командой:
chcon -Rt svirt_sandbox_file_t /var/lib/docker
Примеры команд Docker.
Команда выводит общую информацию
Состояние docker-engine:
sudo docker info
Статистику docker:
sudo docker stats
Информацию о кешированных образах:
sudo docker images
Команда для выкачивания оригинального образа из облака
sudo docker pull alpine
По умолчанию лезет на hub.docker.com Если вы знаете, что есть какое-то свое облако, то адрес необходимо указывать полностью:
sudo docker pull dockerrepo.vasya.com/proect/front
Запуск проекта
sudo docker run -i -t alpine /bin/bash
В этом случае, мы указываем, что нам необхдимо запустить проект alpine в интерактивном режиме, и внутри контейнера запустить процесс /bin/bash. В этом случае, если локально нет образа, то система сначала выполнит docker pull и только затем уже его запустит.
Управленние запущенными контейнерами
Запуск контейнера с определенным именем.
sudo docker run –-name our_container -it ubuntu /bin/bash
Если мы выйдем из контейнера, то он прекратит свою работу. Для того, чтобы запустить его снова, можно воспользоваться этой командой:
sudo docker start container_name
Для того, чтобы остановить контейнер, используйте эту команду:
sudo docker stop container_name
Docker - инструмент создания инфраструктуры.
Docker (Докер) — программное обеспечение с открытым исходным кодом, применяемое для разработки, тестирования, доставки и запуска веб-приложений в средах с поддержкой контейнеризации. Он нужен для более эффективного использование системы и ресурсов, быстрого развертывания готовых программных продуктов, а также для их масштабирования и переноса в другие среды с гарантированным сохранением стабильной работы.
Преимущества использования Docker
- Минимальное потребление ресурсов
- Скоростное развертывание
- Удобное скрытие процессов
- Работа с небезопасным кодом
- Простое масштабирование
- Удобный запуск
- Оптимизация файловой системы
Компоненты Docker
- Docker-демон (Docker-daemon) — сервер контейнеров, входящий в состав программных средств Docker. Демон управляет Docker-объектами (сети, хранилища, образы и контейнеры). Демон также может связываться с другими демонами для управления сервисами Docker.
- Docker-клиент (Docker-client / CLI) — интерфейс взаимодействия пользователя с Docker-демоном. Клиент и Демон — важнейшие компоненты «движка» Докера (Docker Engine). Клиент Docker может взаимодействовать с несколькими демонами.
- Docker-образ (Docker-image) — файл, включающий зависимости, сведения, конфигурацию для дальнейшего развертывания и инициализации контейнера.
- Docker-файл (Dockerfile) — описание правил по сборке образа, в котором первая строка указывает на базовый образ. Последующие команды выполняют копирование файлов и установку программ для создания определенной среды для разработки.
- Docker-контейнер (Docker-container) — это легкий, автономный исполняемый пакет программного обеспечения, который включает в себя все необходимое для запуска приложения: код, среду выполнения, системные инструменты, системные библиотеки и настройки.
- Docker-volume — эмуляция файловой системы для осуществления операций чтения и записи. Она создается автоматически с контейнером, поскольку некоторые приложения осуществляют сохранение данных.
- Реестр (Docker-registry) — зарезервированный сервер, используемый для хранения docker-образов. Примеры реестров:
- Docker-хост (Docker-host) — машинная среда для запуска контейнеров с программным обеспечением.
- Docker-сети (Docker-networks) — применяются для организации сетевого интерфейса между приложениями, развернутыми в контейнерах.
Как работает Docker
Работа Docker основана на принципах клиент-серверной архитектуры, которая основана на взаимодействии клиента с веб-сервером (хостом). Первый отправляет запросы на получение данных, а второй их предоставляет.
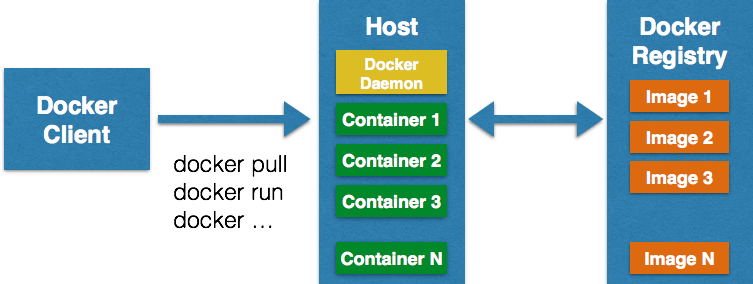
Схема работы
- Пользователь отдает команду с помощью клиентского интерфейса Docker-демону, развернутому на Docker-хосте. Например, скачать готовый образ из реестра (хранилища Docker-образов) с помощью команды
docker pull. Взаимодействие между клиентом и демоном обеспечивает REST API. Демон может использовать публичный (Docker Hub) или частный реестры. - Исходя из команды, заданной клиентом, демон выполняет различные операции с образами на основе инструкций, прописанных в файле
Dockerfile. Например, производит их автоматическую сборку с помощью командыdocker build. - Работа образа в контейнере. Например, запуск docker-image, посредством команды
docker runили удаление контейнера через командуdocker kill.
Примеры применения
- Быстрая доставка приложений (команды docker pull и docker push) позволяет организовать коллективную работу над проектом. Разработчики могут работать удаленно на локальных компьютерах и выполнять пересылку фрагментов кода в контейнер для тестов.
- Развертывание и масштабирование — контейнеры работоспособны на локальных компьютерах, серверах, в облачных онлайн-сервисах. Их можно загружать на хостинг для дальнейшего тестирования, создавать (docker run), останавливать (docker stop), запускать (docker start), приостанавливать и возобновлять (docker pause и docker unpause соответственно).
- Множественные нагрузки — осуществление запуска большого количества контейнеров на одном и том же оборудовании, поскольку Docker занимает небольшой объем дисковой памяти.
- Диспетчер процессов — возможность мониторинга процессов в Docker посредством команд docker ps и docker top, имеющими схожий синтаксис с Linux.
- Удобный поиск — в реестрах Docker он осуществляется очень просто. Для этого следует использовать команду docker search.
Установка докера
#!/bin/bash
apt update
apt install -y docker.io
groupadd docker
usermod -aG docker $USER
Две последние команды необходимы для того, чтобы текущий пользователь мог управлять контейнерами, не запрашивая повышенных привелегий.
Управлением демоном
Запуск демона:
systemctl start docker
Остановка демона:
systemctl stop docker
Включение/отключение автозагрузки демона:
systemctl enable/disable docker
При добавлении ключа --now - выполняет команду не дожидаясь перезагрузки. В противном случае, команда выполнится только после перезагрузки.
Dockerfile, создание docker image.
Dockerfile
Представим, приложение уже работает на вашей машине, но еще не имеет образа. Для того, чтобы получить docker образ, нам необходимо описать его.
Создадим инструкцию для сборки образа
В папке с проектом(мы рассматриваем node проект) создадим файлы:
touch Dockerfile
Для того, чтобы в докер не попапи ненужные файлы - рядом создадим dockerignore и впишем в него всё, что нам не нужно.
touch .dockerignore
Пример Dockerfile:
#Выберем базовый образ из которого мы будем создавать наш проект
FROM node:10-apline
# Укажем папку внутри докера, которая будет являться домашней при выполнении различных команд
WORKDIR /usr/src/app
# Скопируем из папки с проектом все файлы по маске package*.json в папку WORKDIR
COPY package*.json ./
# Запускаем установку пакетов npm
RUN npm install
# Копируем всё что осталось в папке с проектом в папку WORKDIR
COPY . .
# Указываем порт, через который будет доступен наш проект
EXPOSE 3000
# Указываем команду которая будет работать в тот момент, когда запустится контейнер
CMD["npm", "start"]
Список ключей используемых при создании образа
| Ключ | Назначение |
|---|---|
| FROM | Указываем на основе которого из образов будем создавать новый образ |
| MAINTAINER | Указываем автора созданного образа |
| RUN | Запукаем команды в внутри контейнера необхдимые для работы образа |
| CMD | Команда которая будет выполнена при запуске контейнера(может быть только одна) |
| EXPOSE | Говорит докеру, что контейнер слушает на определенном порту |
| ENV | Указываем с каким переменным окружением необходимо создавать контейнер |
| ADD | Копирует файлы, папки, URL и добавляет их в файловую систему образа, может распаковать архив |
| COPY | Копирует файлы, папки из и по указанному пути |
| ENTRYPOINT | Позволяет задавать команду запуска контейнера, при этом при старте указывать ключи запуска этого контейнера, переопределяет CMD |
| USER | Указывает имя пользователя под которым будет происходить выполнение команд RUN, CMD, ENTRYPOINT внутри контейнера |
| WORKDIR | Указываем директорию внутри которой будет происходить выполнение команд RUN, CMD, ENTRYPOINT, COPY, ADD |
| ARG | Определяем переменные, которые могут быть переданы билдеру при запуске docker build используя ключ --build-arg <varname>=<value> |
Билдим проект
Создаем билд с помощью команды:
docker build . -t firstimage
Ожидаем заверешения команды. Для этого может потребоваться много времени.
В случае, если билд завершился неудачно, смотрим что за ошибка и правим Dockerfile
После завершения: мы можем посмотреть на наш firstimage в списке, который можно получить с помощью команды:
docker image
Запуск нашего проекта
Чтобы запустить наш проект - необходимо указать несколько параметров:
docker run -p 80:3000 firstimage
-p - говорит о том, что мы мапируем(прим. ред. mapping - сопоставление) системный 80 порт в порт(помните внутри контейнера использовали EXPOSE 3000) внутри контейнера.
Заходим на http://localhost и убеждаемся, что наше приложение доступно внутри контейнера.
Containerd
В качестве альтернативы можно воспользоваться другим решением.
Запуск
Вот пример того, как можно запустить контейнер с использованием ctr:
Сначала убедитесь, что у вас есть образ контейнера, который вы хотите запустить. Если у вас его нет, вы можете сначала его загрузить с помощью ctr командой, например:
ctr images pull docker.io/library/alpine:latest
Затем запустите контейнер с помощью ctr run команды, указав необходимые параметры, например:
ctr run --rm -t --net-host docker.io/library/alpine:latest my-container sh
Здесь:
-
--rm- указывает на то, что контейнер должен быть удален после завершения работы -
-t- выделяет псевдотерминал для контейнера -
--net-host- позволяет контейнеру использовать сеть хоста -
docker.io/library/alpine:latest- образ контейнера, который мы будем использовать -
my-container- имя контейнера -
sh- команда, которая будет выполнена внутри контейнера (в данном случае, запуск оболочки sh) Таким образом, вы сможете запустить контейнер на хосте только с помощью containerd. 🚀
Сборка
Для сборки образа с помощью containerd вам обычно требуется создать и сконфигурировать контейнер с помощью ctr CLI (Command Line Interface). Вот пример того, как можно собрать образ с использованием containerd:
Установите containerd и ctr CLI на вашем хосте. Создайте конфигурационный файл для контейнера (например, config.toml):
[
process
]
args = ["echo", "Hello, World!"]
Создайте снимок (snapshot) с этим содержимым:
ctr snapshot create my-snapshot my-snapshot-bundle bundle.tar config.toml
Создайте контейнер с использованием этого снимка:
ctr container create my-container --snapshot my-snapshot
Запустите контейнер:
ctr container start my-container
Теперь у вас есть контейнер, запущенный с заданным содержимым. Для создания образа вы можете осуществить экспорт контейнера в архив и использовать его в дальнейшем:
ctr snapshot mount my-snapshot mountpoint
tar -C mountpoint -c . | docker import - my-image:tag
Образ my-image:tag теперь содержит содержимое вашего контейнера и может быть запущен через docker run.
Учтите, что containerd предоставляет более низкоуровневый доступ к контейнерам, поэтому процесс сборки образов может потребовать больше ручной работы и конфигурирования по сравнению с более высокоуровневыми инструментами типа Docker.
Docker swarm
Пример ansible для установки и настройки docker swarm
Описание
Что необходимо на входе
4 хоста с предустановленной debian ОС на борту. В моем случае это 4 виртуальные машины созданные методом копирования пустой установленной системы Debian ОС.
Что получим на выходе
Кластер docker-swarm с 4мя нодами: 1 менеджер и 3 воркера Кластер glusterfs на всех 4х нодах. Файл размещенные по пути /mnt будут синхронизироваться на всех хостах. Это позволит запускать контейнеры на любой ноде зная, что данные будет доступны для любого контейнера на любой ноде.
Необходимые ansible параметры для настройки хостов
Подготавливаем inventory.ini
[manager]
manager ansible_host=192.168.1.46 ansible_user=USERNAME
[nodes]
node1 ansible_host=192.168.1.61 ansible_user=USERNAME
node2 ansible_host=192.168.1.67 ansible_user=USERNAME
node3 ansible_host=192.168.1.96 ansible_user=USERNAME
В файле мы разделили хосты на 2 группы:
- manager - хосты для управления кластером
- nodes - хосты для работы кластера
Необходимо указать
- имена хостов:
manager,node1,node2,node3указаны для примера, эти имена будут использоваться для того, чтобы задать имена хостам. - ansible_host - ip адрес хоста
- ansible_user - пользователь под которым будет происходить настройка серверва.
в случае использования Debian часто приходится отдельно добавлять пользователя USERNAME в группу sudo. Для этого нужнно установить sudo, и добавить пользователя в группу sudo командой под супер пользователем.
su // ввести root пароль
/usr/sbin/useradd -aG sudo USERNAME
Playbook для настройки сервера
Данный playbook выполняется для всех хостов в файле inventory.ini
#play-hostconfig.yaml
- name: Prepear hosts
hosts: all
become: true
tasks:
- name: Изменение имени хоста
ansible.builtin.hostname:
name: "{{ inventory_hostname }}"
# Шаг может быть пропущен если вы используете внешний dns
- name: Создаем dns записи для нашего кластера
lineinfile:
dest: /etc/hosts
regexp: '.*{{ item }}$'
line: '{{ hostvars[item].ansible_default_ipv4.address }} {{item}}'
state: present
with_items: '{{ groups["all"] }}'
- name: Установка пакетов для поддержки HTTPS в apt
apt:
name:
- apt-transport-https
- ca-certificates
- curl
- gnupg2
- software-properties-common
state: present
Устновка glusterfs
Приведенный пример ниже, устанавливает на 4 хоста glusterfs - создает папку и сервис который синхронизирует её между серверами, а так же устанавливает docker.
#play-glusterfs.yaml
---
- name: Устанавливаем необходимые компоненты
hosts: all
become: true
tasks:
- name: Обновляем кэш
apt:
update_cache: true
- name: Устанавливаем GlusterFS сервер
apt:
name: glusterfs-server
state: present
- name: Запускаем glusterd сервис
systemd:
name: glusterd
state: started
enabled: true
- name: Создаем /gluster/volumes папку
file:
path: /gluster/volumes
state: directory
mode: '0755'
owner: root
group: root
- name: Применяем GlusterFS конфигурацию для manager
hosts: manager
become: true
tasks:
- name: Проверяем доступность нод
command: "gluster peer probe {{ item }}"
ignore_errors: true
with_items: '{{ groups["nodes"] }}'
# Требует доступности хостов друг другу во всех направлениях
- name: Create gluster volume staging-gfs
command: >
gluster volume create staging-gfs replica 4
manager:/gluster/volumes
node1:/gluster/volumes
node2:/gluster/volumes
node3:/gluster/volumes
force
register: volume_create_result
changed_when: "'Volume successfully created' in volume_create_result.stdout"
ignore_errors: true
- name: Создаем раздел staging-gfs для glusterfs
command: gluster volume start staging-gfs
ignore_errors: true
- name: Создаем автомонтирование раздела staging-gfs на всех хостах
hosts: all
serial: 1
become: true
tasks:
- name: Обновляем fstab
lineinfile:
dest: /etc/fstab
regexp: '.*staging-gfs.*'
#line: localhost:/staging-gfs /mnt glusterfs defaults,_netdev,backupvolfile-server=localhost,x-systemd.requires=network-online.target 0 0
line: localhost:/staging-gfs /mnt glusterfs defaults,_netdev,noauto,x-systemd.automount 0 0
state: absent
- name: Создаем задачу при запуске системы "@reboot mount.glusterfs localhost:/staging-gfs /mnt"
ansible.builtin.cron:
name: "mount for reboot"
special_time: reboot
job: "sleep 20 && /usr/sbin/mount.glusterfs localhost:/staging-gfs /mnt > /root/mount.log 2>&1"
state: present
- name: Перезагружаем сервер после завершения конфигурации
ansible.builtin.reboot:
Заведение серверов в dockekr swarm.
#play-docker.yaml
---
- name: Установка docker
hosts: all
become: true
tasks:
- name: Добавление GPG-ключа Docker
apt_key:
url: https://download.docker.com/linux/debian/gpg
state: present
- name: Добавление репозитория Docker
apt_repository:
repo: deb https://download.docker.com/linux/debian buster stable
state: present
- name: Установка Docker Engine
apt:
name: docker-ce
state: present
- name: Добавление текущего пользователя в группу docker
user:
name: user
append: yes
groups: docker
- name: Меняем владельца на docker для /mnt папки
file:
path: /mnt
owner: root
group: docker
recurse: yes
- name: Создание и настройка Swarm кластера
hosts: managers
gather_facts: false
tasks:
- name: Инициализация Swarm кластера
command: docker swarm init
ignore_errors: true
register: swarm_init_output
changed_when: false
- debug:
var: swarm_init_output.stdout
- set_fact:
join_command: "{{ swarm_init_output.stdout_lines[-2] }}"
- name: Присоединение узлов к кластеру
hosts: nodes
gather_facts: false
tasks:
- name: Присоединение к кластеру
command: "{{ hostvars['manager'].join_command }}"
changed_when: false
ignore_errors: true
register: swarm_join_output
- debug:
var: swarm_join_output.stdout
# В зависимости от того добавляем или удаляем метки, нужно будет изменить `changed_when` параметр заменить на true/false.
- name: Настройка меток для узлов кластера
hosts: manager
gather_facts: false
tasks:
- name: Добавление меток для узлов кластера
command: docker node update --label-add {{ item.label }} {{ item.node }}
with_items: "{{ node_labels }}"
changed_when: false
- name: Удаление меток для узлов кластера
command: docker node update --label-rm {{ item.label }} {{ item.node }}
with_items: "{{ node_labels }}"
changed_when: false
vars:
node_labels:
- { label: "env=prod", node: "node1" }
- { label: "env=staging", node: "node2" }
- { label: "env=dev", node: "node3" }
Команда для применения конфигурации с помощью ansible
ansible-playbook -i inventory.ini play-hostconf.yaml -kK
ansible-playbook -i inventory.ini play-glusterfs.yaml -kK
ansible-playbook -i inventory.ini play-docker.yaml -kK
Ключи -kK говорят о том, что я не использую id_rsa ключ. Вместо этого ввожу пароль для пользователя и для root доступа в ручную в момент запуска команды ansible-playbook. Если ваши хосты имеют установленные ключи, то можно опустить -kK.
Docker-compose
Создание инфраструктуры для работы приложения.
Клонируем проект:
Нам понадобится приложение,которое мы собираемся развернуть на проекте.
git clone https://github.com/gasick/docker-compose-exempleapp --branch onlyapp
Если вы не знаете с чего начать, тогда смотрите в README проекта. Обычно в нем разрабочики указывают подготовительные шаги для того, чтобы развернуть приложени локально. Это позволит набросать какой-то простой пример Dockerfile от которого уже можно будет двигаться дальше. Ошибки при создании докер файла будет говорить, о том, что нам необхдимо добавить в докер, чтобы приложение могло запуститься.
Наша задача автоматизировать шаги развертывания приложения.
Результатом нашей работы должна получиться подобнаяструктура папок:
.
├── docker-compose.yml
├── Dockerfile
├── example.env
└── todoapp
├── go.mod
├── go.sum
└── todo.go
-
todoapp- папка в которой хранится проект который необходимо развернуть -
Dockerfile- файл создания контейнера с приложением внутри -
docker-compose.yml- файл конфигурацией инфраструктуры нашего приложения, то есть наше приложение обернутое в контейнера, а так же все сервисы необходимые для его работы. -
example.env- пример настроек для простоты перемещения проекта.
Упаковываем приложение в docker контейнер
В нашем примере, мы воспользуемся двумя контейнерами. Один будет использоваться для построения приложения, другой уже для его запуска.
Dockerfile
# Указываем какой образ мы будем использовать в качестве основы проекта, и присвоем ему имя build
FROM golang:1.16 as build
# Устанавливаем необходимое по, в данном случае это только git но этот список может быть сильно больше.
RUN apt update && apt install -y git
# Указываем рабочую папку
WORKDIR /app
# Копируем в рабочую папку необходимые файлы
COPY todoapp/go.mod .
COPY todoapp/go.sum .
# Подготавливаем окружение, скачиваем необхдимые для построения зависимости.
RUN go mod download
# Копируем проект
COPY todoapp .
# Запускаем build проекта
RUN go build -o /out/app /app
# Теперь на основе нового образа будем создавать сам рабочий контейнер.
FROM fedora
# Копируем из базового образа наше приложение для указания образа используется ключ --from=build
COPY --from=build /out/app /app
# Указываем директиву с которой будет запускаться проект
CMD ["/app"]
# Так как проект слушает порт для подключения клиентов, выставляем его.
EXPOSE 8000
Тепреь давайте прверим, что Dockerfile коректен и мы можем упаковать наше приложение:
docker build -t test .
Если билд прошел, и все шаги отработали идем дальше. Запускать проект пока не нужно, он всё равно выдаст ошибку, так как для работы необходим Postgres.
Создаем docker-compose, связываем приложение и базу данных в одну инфраструктуру.
docker-compose.yml
version: "3"
services:
todoapp:
build: .
ports:
- 8000:8000
env_file:
- example.env
depends_on:
- postgres
postgres:
image: postgres:13-alpine
restart: always
env_file:
- example.env
volumes:
- ./postgres/data:/var/lib/postgresql/data
- ./postgres/dumps:/dumps
example.env
Для полноценной работы в проекте нам нужен example.env.
Вынесение переменных окружения позволяет легко переносить проект с сервера на сервер, так же упрощает обслуживание. И настройку приложения в процессе работы, не прибегая к помощи разработчиков.
Для данного проекта файл будет являтся ключничей, из него postgres будет знать с какими данными создавать пользователь/пароль/бд, а приложение будет знать с какими параметрами подключаться к ней:
POSTGRES_DB=db
POSTGRES_USER=user
POSTGRES_PASSWORD=password
POSTGRES_HOST=postgres
POSTGRES_PORT=5432
Во время разрабтки, и работы сервера в целом, мы привыкли к тому, что все общение различных сервисов происходит через localhost. В случае с docker-compose это не работает. Для понимания того, что произойдет после поднятия docker-compose, представьте себе локальную сеть, в которй большое количество серверов. Все сервисы запущенные на одной машиние, теперь разнесены таким образом, чтобы на каждой машине в сети работал только один сервис, то есть общение может быть только исключительно через локальную сеть, в реальной сети такое общение будет происходить с помощью ip, в docker-compose мы указываем названия сервисов.
То есть во время работы приложение и бд не будут доступны через localhost, друг для друга они будут доступны только через свои имена: todoapp, postgres.
Проверяем работу
Для запуска проекта выполните:
docker-compose up
Для проверки проекта в соседнем терминале:
curl http://localhost:8000/ -v
В ответе должна быть строка: Всё работает!
Для того, чтобы проверить связь приложения и бд, воспользуемся другой командой:
curl -H "Content-Type: application/json" http://localhost:8000/todos/ -d '{"name":"Wash the garbage","description":"Be especially thorough"}' -v
В ответ прилетит json с ID нашего todo
Чтобы проверить, что у нас всё работает, из текущей папки:
- входим в docker контейнер
docker-compose exec postgres psql -U user db
- Просим показать содержание таблицы todos
select *from todos;
В ответе видим таблицу с нашими вводными данными:
id | name | description
----+------------------+------------------------
1 | Wash the garbage | Be especially thorough
(1 row)
Docker-compose файл.
Docker-compose - инструмент для совместного запуска несколких контенеров. Основой для docker-compoes является yaml-файл с настройками. Удобство заключается в том, что единожды написанный docker-compose.yml можно легко перенести с устройства на устройство.
Установка
sudo curl -L "https://github.com/docker/compose/releases/download/1.29.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-compose
sudo ln -s /usr/local/bin/docker-compose /usr/bin/docker-compose
Третья строчка скрипта дает нам возможность использовать docker-compose от имени сисетмы, если этот команда не будет выполнена. команда docker-compose потребует указания полноценного пути расположения.
Пример написания docker-compose
Пример взят с docs.microsoft.com
version: "3.7"
services:
app:
image: node:12-alpine
#build: .
command: sh -c "yarn install && yarn run dev"
ports:
- 3000:3000
working_dir: /app
volumes:
- ./:/app
environment:
MYSQL_HOST: mysql
MYSQL_USER: root
MYSQL_PASSWORD: secret
MYSQL_DB: todos
networks:
app_net:
mysql:
image: mysql:5.7
volumes:
- todo-mysql-data:/var/lib/mysql
environment:
MYSQL_ROOT_PASSWORD: secret
MYSQL_DATABASE: todos
networks:
app_net:
volumes:
todo-mysql-data:
networks:
app_net:
driver: bridge
Ключевые слова используемые в docker-compose:
| Ключи | Применение |
|---|---|
| build | Указывает путь откуда брать Dockerfile для создания образа |
| args | Указание аргументов билда которые требуются во время создания образа |
| command | Переписывает CMD указанную в Dockerfile |
| devices | Мапирование физических устройств в рабочий контейнер |
| depends_on | Указание зависимости сервисов друг от друга. Зависимый сервис будет запускаться последний |
| dns | Указанный в ручуню DNS сервер |
| entrypoint | Переписывает ENTRYPOINT директиву из Dockerfile |
| env_file | Добавление переменных с помощью файла переменных окружения |
| environment | Явное указание переменных в контейнер |
| expose | Выставление портов контейнера, они будут доступны только linked сервисам, могут быть указаны только внутренние порты. |
| image | Указание образа, который будет взят для старта контейнера |
| links | Связывание контейнеров разных сервисах |
| logging | Настройки логирования для сервиса. |
| networks | Сеть к которой будет присоденен сервис |
| ports | Маирование портов из контейнера в хост систему |
| volumes | Мапирование папок из хост системы в контенер |
Docker-compose cli
Сборка контенера, имеет смысл если в yaml файле присутствует директива build.
Можно использовать ключ --no-cache, в таком случае игнорируются кэшированные образы.
docker-compose build
Запуск приложения. В запуск можно добавить --build ключ, тогда docker-compose перебилдит незакешированные шаги.
docker-compose up
Docker-compose останавливает и удаляет запущенные контенеры, согласно yaml конфигурации.
То есть выполянется 2 команды docker: docker stop и docker rm
docker-compose stop
Отображает запущенные контейнеры принадлежащие yaml файлу.
docker-compose ps
ВНИМАНИЕ! Выполенение команда, в отличии от
docker, должно быть с в папке с yaml файлом. Командаdockerможет выполнятся из любой папки.
Gitlab
Подготовка сервера для обновления версии приложения.
В этой инструкции мы попытаемся объединить уже ранее собранные нами конфигурационные файлы во едино. Что для этого нужно
Подготовим север для запуска сервиса. Установим необходимое ПО
#!/bin/bash
apt update
apt install -y docker.io nginx
groupadd docker
usermod -aG docker $USER
sudo curl -L "https://github.com/docker/compose/releases/download/1.29.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-compose
sudo ln -s /usr/local/bin/docker-compose /usr/bin/docker-compose
Настроим docker-compose и запустим проект
Настройку проекта мы можем опустить, там как мы её уже изучали в разделе про docker-compose. Обычно к этому моменту мы должны уже иметь репозиторий, который должен работать локально. Его достаточно склонировать, и использовать для запуска.
В проекте не должны использоваться порты 80 и 443, так как это порты используемые nginx.
Для полноценной работы, нам необхдимо изменить адрес контейнера в docker-compose, так как теперь мы не будем собирать контейнер на сервер, за нас это делает pipeline, нам необходимо заменить директиву build на image таким образом, мы скажем докеру, что ему необходимо брать образ откуда то еще.
Настроим скрипт выливки на сервер и проверим его работоспособность.
Добавим в проект deploy.sh - скрипт который позволит нам актоматически равзертывать новую версию на сайте.
#!/usr/bin/env bash
#Не забываем авторизоваться в docker, если используем закрытый или частный репозиторий
docker login -u КАКОЙ_ТО-token -p КАКОЙ-ТО-ПАРОЛЬ какой-то.регистри.com
cd "АДРЕС/МЕСТОПОЛОЖЕНИЯ/ПАПКИ/ПРОЕКТА"
# Вытягиваем новую версию
docker-compose pull;
# Останавливаем старый сервис
docker-compose down;
# Запускаем новую версию
docker-compose up -d
Настраиваем nginx и получаем рабочий сервис.
Теперь мы дошли до того, чтобы настроить nginx. Nginx нужен для того, чтобы мы могли настроить работу сервиса по доменному имени.
Для работы нашего сервиса воспользуемся готовым конфигом nginx.conf
server{
listen 80;
server_name videomanager-test.garpix.com;
location / {
proxy_pass http://web:8080;
proxy_set_header Host $http_host;
proxy_set_header Connection "upgrade";
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Upgrade $http_upgrade;
proxy_connect_timeout 600;
proxy_send_timeout 600;
proxy_read_timeout 600;
send_timeout 600;
}
}
Пример создания Pipeline на основе Gitlab-ci.
Рассмотрим пример создания pipeline на основе gitlab-ci.yaml
Давайте посмотрим какие пункты мы можем внести gitlab.
В gitlab-ci.yaml будет внесены пукнты 3-5 прошлой статьи. То есть, gitlab-ci будет отвечать за создание, тестирование и выпуск образа и развертывание его в рабочем окружении.
- Добавим в проект файл gitlab-ci.yml.
- Заполним его, для этого воспользуемся готовым шаблоном:
image: docker:latest
variables:
DOCKER_DRIVER: overlay
CONTAINER_TEST_IMAGE: $CI_REGISTRY/$CI_PROJECT_PATH:$CI_COMMIT_REF_NAME
CONTAINER_RELEASE_IMAGE: $CI_REGISTRY/$CI_PROJECT_PATH:latest
services:
- docker:dind
stages:
- build
- test
- release
- deploy
build:
stage: build
script:
- docker login -u gitlab-ci-token -p $CI_JOB_TOKEN $CI_REGISTRY
- docker build --pull -t $CONTAINER_TEST_IMAGE . --build-arg=secret_key=secret
- docker push $CONTAINER_TEST_IMAGE
only:
- tags
test:
image: $CI_REGISTRY/$CI_PROJECT_PATH:$CI_COMMIT_REF_NAME
stage: test
services:
- postgres:11-alpine
variables:
SECRET_KEY: runner
POSTGRES_DB: runner
POSTGRES_USER: runner
POSTGRES_PASSWORD: runner
POSTGRES_HOST: postgres
POSTGRES_PORT: 5432
TEST: 1
script:
- python3 /code/backend/manage.py qa
only:
- tags
release:
stage: release
script:
- docker login -u gitlab-ci-token -p $CI_JOB_TOKEN $CI_REGISTRY
- docker pull $CONTAINER_TEST_IMAGE
- docker tag $CONTAINER_TEST_IMAGE $CONTAINER_RELEASE_IMAGE
- docker push $CONTAINER_RELEASE_IMAGE
only:
- tags
deploy:
image: kroniak/ssh-client
stage: deploy
script:
- eval $(ssh-agent -s)
- ssh-add <(echo "$SSH_PRIVATE_KEY")
- ssh -o StrictHostKeyChecking=no -p $TESTPORT $TESTUSER@$STAGINGHOST make --directory=$TESTPATH deployfront TAG=$CI_COMMIT_REF_NAME
only:
- tags
# when: manual
Для начала разберем переменные используемые в данном файле конфигурации, но которые необхдимо задать в окружении gitlab(Settings->CI\CD->Variables->"Add variables" уберите галочку "Protected variable" для ознакомления она вам не понадобится):
- SSH_PRIVATE_KEY = приватная часть ключа для доступа к удаленной машине
- TESTPORT = порт на котором слушает ssh сервер
- TESTUSER = пользователь у которого есть публичная часть доступа к серверу.
- TESTHOST = адрес хоста,(ip или dns имя)
- TESTPATH = путь до папки проекта.
Все остальные переменные перечислены в секции variables (используются в местах где они начинаются с символа$) геренируются в процессе запуска скрипта. Берутся они из gitlab окружения, можно найти в документации к gitlab.
Теперь рассмотрим стадии, в приведенном примере в разделе stages их 4 стадии:
- build - сбор образа
- test - тестирование
- release - выпуск
- deploy - развертывание
Рассмотрим их более подробно:
Для начала общие части
- image - образ внутри которого будет выполняться скрипт
- stage - стади к которой относится текущая секция
- services - дополнительные сервисы необходимые для проекта
- script - непосредственно выполнение логики.
Производство ПО как конвеер.
Что это за конвеер?
Создание программного обеспечения представялет из себя несколько этапов. Рабочий процесс может отличаться от текущего, но в основном подходы отличаются очередью выполнения.
- Написание кода - не представляет ничего сложного:
- Забираем изменения из репозизтория
- Вносим изменения и коммитим
- Пуши изменения в репозиторий
- Публикация его в репозиторий - после того как вы его запушили в репозиторий
- Ваши изменения требуют мердж реквест в
testветку - После того как мердж реквест пройден(изменения одобрил ведущий разрабочик)
- Дальше изменения переходят к пункту 3 и идут дальше.
- Ваши изменения требуют мердж реквест в
- Создание образа(рамках нашего проекта это будет docker)
- Подготавливается образ
- Образ пушится в облако
- Тестирование образа и релиз
- Происходит тестирование
- Если тестирование успешно пройдено, то производится резил образа.
- Развертывание образа
- Запускается скрипт, который тригерит обновления окружения.
Если пункт 5 завершился успешно, то теперь пункт 2 выполняется полностью для ветки master, И дальше опять пункты 3-5, только уже для производственного окружения.
Helm
Основные команды
Для того, чтобы корректно работать с helm, необходимо использовать внешний values.yaml только с измененными строчками. Из values.yaml, что находится в чарте, необходимо выносить только те переменные, которые будет переопределяется. Это позволит оставить values.yaml максимально читабельным.
Установка чарт с приложением
helm install chart-name repo-name/app-name -f values.yaml
или
helm upgrade --install chart-name repo-name/app-name -f values.yaml
или
helm upgrade --install chart-name ./folder-name/ -f values.yaml
-
install- устанавливает приложение, если приложение установленно то команда вызывает ошибку -
upgrade- обновляет текущую конфигурацию(ключ--installпозволяет установить приложение если его нет) -
chart-name- название приложения в k8s -
repo-name- название репозитория из которого берется приложение -
app-name- название приложения в репозитории -
values.yaml- файл с конфигурацией которая переопределяет необходимые параметры. -
./folder-name/- название папки в которой лежит локальный чарт
Проверить применяемое для приложения конфигурацию
helm template repo-name/app-name --version 4.13.0 -f values.yml
Удаление приложения
helm delete chart-name
Получить список доступных версий для приложения
helm search repo -l repo-name/app-name
Если необходимо получить определенную версию
helm pull repo-name/app-name --version 4.14.3 --untar
Создание helm chart
Создаем локальный чарт
helm create app-name
Стуктуру папок которую получим в результате
app-name/
├── .helmignore # Содержит перечень папок и фалов которые будет исключены из результирующего хелм чарта
├── Chart.yaml # Общая информация о чарте
├── values.yaml # Значения по умаолчанию испольуземые в чарте
├── charts/ # Чарты от которых может зависить чарт что вы создаете
└── templates/ # Файлы шаблоны
Новая страница
a^2+b^2=c^2
This sentence uses $ delimiters to show math inline: $\sqrt{3x-1}+(1+x)^2$
$x_{1,2} = \frac{-b \pm \sqrt{b^2-4ac}}{2b} (1)$
Helmfile
Команды
Удаление одного конкретного release
helmfile destroy -l app=prometheus-stack --skip-deps
Обновление только одного конкретного release
helmfile apply -l app=crossplane --skip-deps
Jenkins
Дополнительные возможности
-
timestamp()печатает время выполнения каждого шага -
buildDiscardзадает параметры хранения информации о сборке -
timeoutзадает время ожидания для сборки, используется для того чтобы прервать сборку при зависании.
pipeline {
agent any
options {
timestamps()
buildDiscarder logRotator(daysToKeepStr: '3',
numToKeepStr: '3' )
/* All Project: pipeline
Timeout set to expire in 20 min */
timeout(time: 20, unit: 'MINUTES')
}
stages {
stage('Build') {
options {
/* Stage: Build
Timeout set to expire in 1 min 0 sec */
timeout(time: 1, unit: 'MINUTES')
}
steps {
echo "build ${env.BUILD_ID} on ${env.JENKINS_URL}"
/* Sleeping for 1 min 40 sec */
sleep 100
}
}
}
}
-
buildDiscarder- сохранять артефакты и логи для определенного числа последних запусков конвейера -
checkoutToSubdirectory- выполняет автоматическую проверку системы управления версиями в подкаталоге рабочей области -
disableConcurrentBuilds- запретить одновременное выполнение конвейера -
disableResumeне позволяет конвейеру возобновить работу после перезапуска контроллера. -
newContainerPerStage- Используется с агентом верхнего уровня docker или dockerfile. Если указано, каждый этап будет запускаться в новом экземпляре контейнера на том же узле, а не все этапы, выполняемые в одном экземпляре контейнера. -
overrideIndexTriggers- Позволяет переопределить стандартную обработку триггеров индексации ветвей. -
quietPeriod- Установите период молчания в секундах для конвейера, переопределив глобальное значение по умолчанию. -
retryВ случае сбоя повторите попытку запуска всего конвейера указанное количество раз. -
skipDefaultCheckoutПо умолчанию в директиве агента пропускать извлечение кода из системы управления версиями. -
skipStagesAfterUnstableПропускайте этапы после того, как состояние сборки изменилось на НЕСТАБИЛЬНЫЙ -
timeoutустановите период ожидания для запуска конвейера, по истечении которого Дженкинс должен прервать конвейер. -
timestampsДобавьте ко всему выводу на консоль, время для действий. -
buildDiscarder
options { buildDiscarder(logRotator(numToKeepStr: '1')) }
- checkoutToSubdirectory
options { checkoutToSubdirectory('foo') }
- disableConcurrentBuilds
options { disableConcurrentBuilds() }
- disableResume
options { disableResume() }
- overrideIndexTriggers
options { overrideIndexTriggers(true) }
- preserveStashes
options { preserveStashes(buildCount: 5) }
- quietPeriod
options { quietPeriod(30) }
- retry
options { retry(2) }
- skipDefaultCheckout
options { skipDefaultCheckout() }
- skipStagesAfterUnstable
options { skipStagesAfterUnstable() }
- timeout
options { timeout(time: 1, unit: 'HOURS') }
- timestamps
options { timestamps() }
- parallelsAlwaysFailFast
options { parallelsAlwaysFailFast() }
Заметки
shell output
script {
GIT_COMMIT_EMAIL = sh (
script: 'git --no-pager show -s --format=\'%ae\'',
returnStdout: true
).trim()
echo "Git committer email: ${GIT_COMMIT_EMAIL}"
}
Параметризованный конвейер
Типы параметров:
-
stringЭтот параметр позволяет вводить строку. Подпараметры включают в себя description , defaultValue и name. -
textЭтот параметр позволяет пользователю вводить несколько строк текста. -
booleanParamпараметр значения его true/false -
choiceЭтот параметр позволяет пользователю выбирать из списка вариантов. Под параметрами для него являются имя, choices и описание. Здесь choices относится к списку вариантовПервый в списке будет выбран по умолчанию. -
passwordЭтот параметр позволяет пользователю вводить пароль. Для паролей введенный текст скрыт.
Пример:
-
string
parameters { string(name: 'YOURNAME', defaultValue: 'Valera', description: '') } -
text
parameters { text(name: 'TEXT', defaultValue: 'One\n2\nThree\n', description: '') } -
booleanParam
parameters { booleanParam(name: 'Test', defaultValue: true, description: '') } -
choice
parameters { choice(name: 'CHOICES', choices: ['one', '2', 'three'], description: '') } -
password
parameters { password(name: 'PASSWORD', defaultValue: 'SECRET', description: '') }
pipeline {
agent any
parameters {
string(name: 'FIRST_NAME', defaultValue: 'Ivan',
description: 'This is your name')
string(name: 'LAST_NAME', defaultValue: 'Ivanov',
description: '')
text(name: 'MESSAGE', defaultValue: '',
description: 'Enter some information about the news')
booleanParam(name: 'DO_IT', defaultValue: true,
description: '.....')
choice(name: 'CHOICE', choices: ['one', '2', 'Three'],
description: 'Pick something')
password(name: 'PASSWORD', defaultValue: 'SECRET',
description: 'Enter a password')
}
stages {
stage('Example') {
steps {
echo "Hello ${params.FIRST_NAME}"
echo "Biography: ${params.LAST_NAME}"
echo "Toggle: ${params.DO_IT}"
echo "Choice: ${params.CHOICE}"
echo "Password: ${params.PASSWORD}"
}
}
}
}
Синтаксис
Agent - указывает, где запускается весь конвейер или конкретный этап. Agent в верхней части блока pipeline должен быть определен обязательно для выполнения. Отдельные директивы agent может быть указана по необходимости в начале отдельных этапов, чтобы указать, где в этих этапах должен выполняться код.
Параметры для agent:
-
any- Выполните конвейер или этап для любого доступного агента. none - При применении на верхнем уровне блока конвейера глобальный агент не будет выделен для всего выполнения конвейера, и каждый раздел Stage должен содержать свой собственный раздел агента. -
label- Выполните конвейер или этап для агента, доступного в среде Jenkins, с предоставленной меткой. -
node- идентичен label, но у node можно указать дополнительный параметр customWorspace. -
docker- выполнить конвейер или этап с заданным контейнером, который будет динамически подготовлен на узле, предварительно настроенном для приема конвейеров на основе Docker -
dockerfile- выполнить конвейер или этап с контейнером, созданным из файла Docker, содержащегося в исходном репозитории. -
kubernetes- выполнить конвейер или этап внутри модуля, развернутого в кластере Kubernetes. Пример 1: Раздел агента внутри части блока pipeline
pipeline {
agent any
stages {
stage('Build') {
steps {
echo 'Hello Pipeline'
ws('/tmp/hey') {
sh 'pwd'
}
}
}
}
}
Пример 2: Раздел агента внутри stage
pipeline {
agent none
stages {
stage('Build') {
agent any
steps {
echo 'Helo Pipeline'
}
}
stage('Test') {
agent any
steps {
echo 'Test'
}
}
}
}
Environment
**Environment** - определяет последовательность пар ключ-значение, которые будут определены как переменные среды для всех шагов или этапов
Обратите внимание что credentials: tomcat9Cred (Login/Password) должен быть у вас создан в Jenkins что бы вы могли к нему обратиться.
pipeline {
agent any
environment {
javaVersion = '/usr/var/java8'
}
stages {
stage('Example Username/Password') {
environment {
SERVICE_CREDS = credentials('tomcat9Cred')
}
steps {
/* Masking supported pattern matches
of $SERVICE_CREDS
or $SERVICE_CREDS_USR
or $SERVICE_CREDS_PSW */
echo "Service user is $SERVICE_CREDS_USR"
sh 'echo "Service password is $SERVICE_CREDS_PSW"'
}
}
stage('Build') {
steps {
echo "build ${env.BUILD_ID} on ${env.JENKINS_URL}"
echo "This is path ${env.javaVersion}"
echo "This is path $javaVersion"
sh 'printenv'
}
}
}
}
Post
Post - определяет один или несколько дополнительных шагов, которые выполняются после завершения конвейера или этапа
список условий для post:
-
always- выполняется nезависимо от статуса завершения конвейера или этапа. -
aborted- выполняется если конвейер был прерван. -
changed- если статус текущей сборки отличается от статуса предыдущей, выполняются шаги в блоке. -
cleanup- выполнить шаги после всех остальных условий, независимо от всех состояний. -
fixed- выполняется в случае если текущий конвейер или этап был успешным, а прошлый был fail или unstable -
failure- если текущая сборка провалилась, выполнить шаги в блоке. -
success- текущая сборка прошла успешно, выполняются шаги в блоке. -
unstable- выполнить шаги в сборке если состояние было нестабильным. -
unsuccessful- выполняется в случае не успеха. -
regression- выполнятся если текущее с fail или unstable статусе, а предыдущей был успешны
pipeline {
agent any
stages {
stage('Build') {
steps {
sh 'ls -ls'
}
}
}
post {
always {
echo 'always finished'
deleteDir() /* clean up our workspace */
}
aborted {
echo 'Project aborted...'
}
changed {
echo 'Things were different before...'
}
success {
echo 'I succeeded'
}
unstable {
echo 'I am unstable...'
}
failure {
echo 'I failed :/'
}
}
}
Stages
Stages - раздел этапов содержит последовательность из одной или нескольких этапов, тут исполняются основные действия в конвейере.
Stage - входит в stages, и содержит steps
Steps - определяет шаги которые должны быть выполнены для stage. В разделе steps у нас может быть любой допустимый оператор DSL, такой как git , sh , echo и т. д.
pipeline {
agent any
stages {
stage('Test') {
steps {
echo 'testing...'
}
}
stage('Build') {
steps {
echo 'build building'
sh 'ls -l'
}
}
stage('Deploy') {
steps {
echo 'deploy to container'
}
}
}
}